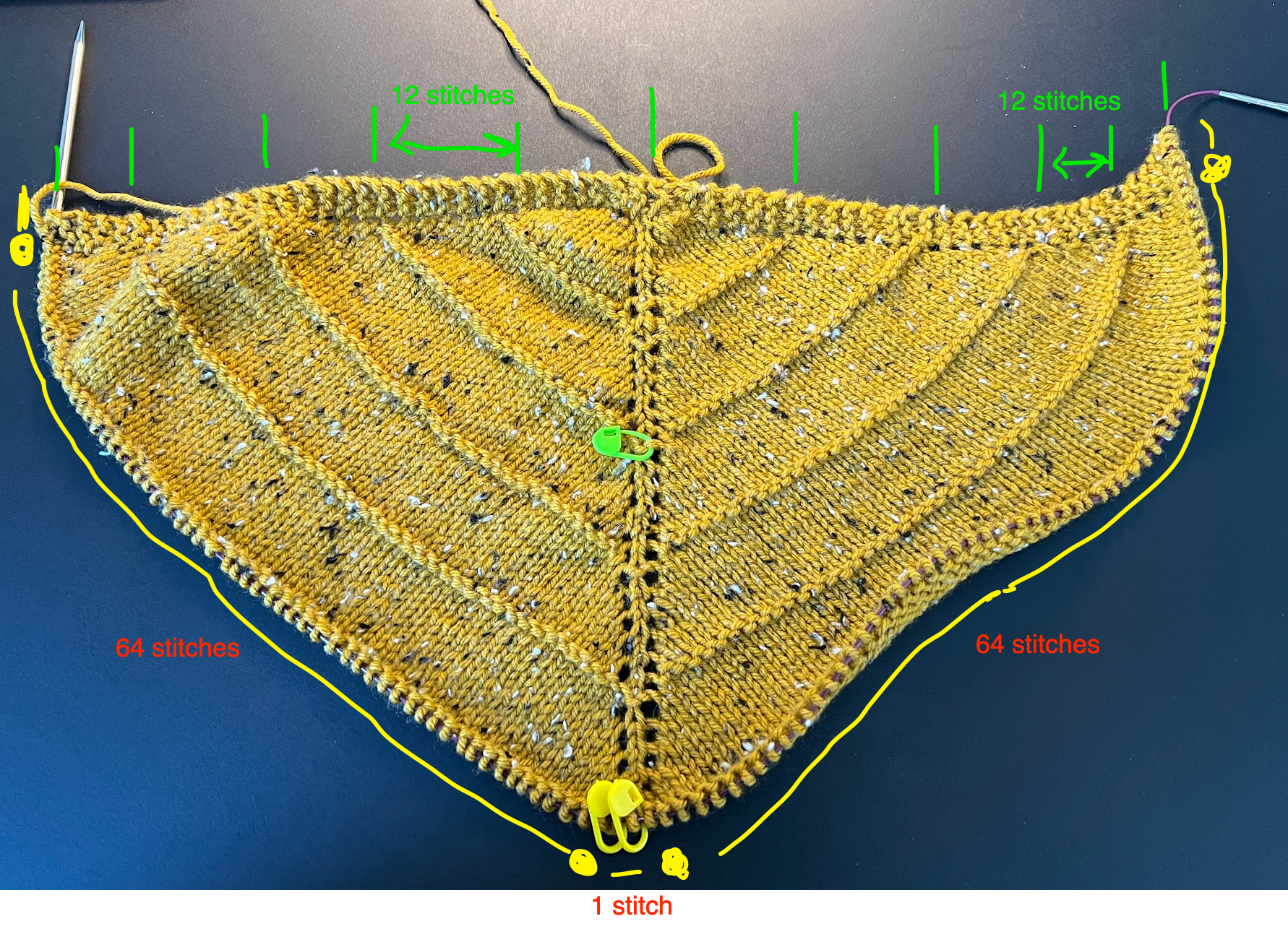
On Thursday, after school, I hopped in an Uber to the airport. I was flying to a conference, the “Teaching Contemporary Mathematics” conference (TCM) held at the North Carolina School of Science and Mathematics. I think I’ve been at least twice over my career, maybe three times, and always found it to be a really solid conference. The big sell for me is that it’s primarily high school math-focused, and most of the sessions are given by actual math teachers about their own teaching practice. And more importantly, it’s felt like forever since I just got to geek out with other math teachers. A fellow teacher from my school and I arrived pretty late and just passed out, with dreams of conference day on Friday.
Although I haven’t blogged in forever, I wanted to at least outline a few things tonight that I can return to. But it’s late and I’m tired, so I’m only going to do a few tidbits.
There were two sessions that got the mathematical side of my brain whirring.
Ryan P gave a talk on “A Rainbow of Random Digits,” where he went from 1D to 2D to 3D to think about a interesting problem. I thought what he showed was beautiful, especially for the 1D and 2D which I could see using with students in a sort of ongoing independent study/investigation. For the 1D question, he asked us if we had two dowels, of length 1 and length 2, and we split the larger dowel into two pieces, what is the probability that the (now three) dowels could form a triangle. A nice fun introductory question with various approaches to answering it. For the 2D question, he asked as a warm up: if you had two numbers chosen randomly between 0 and 1, (a) what is the probability that the sum is greater than the product, and (b) what is the probability that the sum of between 5 and 6? Lovely scaffolding, and the first question requires a little bit of calculus, which is fun. And then the full 2D question (which can be answered using some calculus, but I think it’s even more beautiful without it): if you have two random numbers between 0 and 1, what is the probability that the first non-zero digit of their ratio is a 1? a 2? 3?… 9? Totally fascinating 2D probability space, with lots of “triangle slivers.” To whet your appetite, here it is:

And totally not my intution, but the probability of getting a 1 (33.3%) is greater than the probability of getting a 2 (14.9%) which is greater than the probability of getting a 3 (10.2%), etc. The calculation involves some fun infinite geometric series. All of this was new to me. I also have no idea why getting a 1 digit is more likely than getting a 2 digit which is more likely than getting a 3 digit, etc. My intuition–which was way off–made me think all digits would be equally likely. Now honestly, I don’t know how teachers can actually build something like this problem into their normal classroom practice, but I do know that I’d love to work with a student to get them from the statement of the question to the answer in a lovely set of independent investigations, and some well-thought-out hints to guide. (And maybe chatgpt to write some simple code to do an initial simulation.) My friend and colleague suggested that maybe the distribution might be related to Benford’s law.
The second session that got the mathematical side of my brain whirring was by Bryan S. He had first learned about Conway’s “Rational Tangles” a few years ago, and wanted to present it to us. Wonderfully, I had first learned about these from Conway himself when I was in high school attending Mathcamp (and Conway was a guest lecturer). Conway was an electric speaker — and this one lecture of his imprinted itself on my mind. Now skip forward to this year. I had students work on “Explore Math!” projects and one worked on knot theory. I mentioned in my feedback to one student I had a really cool knot theory-adjacent thing I learned and I could show her. She responded saying “yes, please!” Of course it’s been years since I learned Rational Tangles. And it’s like the universe said “Oh, let me bring Bryan S. to you to remind you about all the nitty gritty of it.” And he was fabulous — a marvelous instructor who somehow managed to convey the excitement, weirdness, inquiry, all in a single short session. The crux of the setup is that you have two ropes held by four people:

There are two moves: T(wist) which has the front right person and back right person switch positions, where the front right person brings their rope under the back right person’s rope, and R(otate) where the four people just rotate clockwise. It turns out that by doing seqences of moves like this, such as TTRTRTTRT (etc.), you can get a pretty tangled tangle in the middle of the two ropes. One question — the main one we talked about — is if you can do a series of Ts and Rs to “undo” the tangle and get back into the original position of just two untangled ropes. Amazingly, a few Mathcampers created a digital version of this twisting and rotating and it took me about 20 minutes today to find it even though I knew it existed and I had played with it before. Here it is!
Another session I went to was Chris B’s Estimathon! I participated in my first estimathon at the Park City Math Institute many years ago (and again, a couple years ago). I hated it both times, for a few years. First, I hate estimating. I love thinking and calculating — but Fermi problems? I get really annoyed because I feel I rarely have the adjacent information that can unlock the problem. Second, the other people (both on my team and on all the other teams) were very, very competitive. I prefer a cooperative board game over a competitive board game, and in this, I think I feel similarly. That being said, I really enjoyed doing the estimathon with Chris and our other math conference participants. It was fun because the other people on my team were chill about it, and also let me sort of work alone at times when I got obsessed with a problem. Here are two example questions we were tackling:

Yes, I went to #5 because you can calculate that. Here’s what the scoring sheet looked like:

So you get to guess a minimum value and a maximum value for the range that the answer is in. And your score is ceiling(maximum/minimum). In other words, take the maximum value, divide it by the minimum value, and round up. So min: 2000, max: 3000 would yield a score of 2, and min: 2000 max: 4000 would also yield a score of 2…. but min: 2000, max: 4001 would yield a score of 3. Your goal is to get the lowest score. At the end, Chris gave us the absolute best idea (which I think he got from his colleague Emily). You have kids find out numbers for something that they are passionate about or would be an expert in. It could be “the number of pokemon” or “how many grandchildren does Sameer’s father have?” And then later in the year, you could create an estimathon out of these numbers — where kids have to see what they know about each other and their passions. I love this as a way for people to get to know each other.
There were two additional sessions that I attended, which were about students and math, and I loved both. First was by Jenny W, Lauren B, and Kevin J, and reminded me of the “5 practices” (https://www.nctm.org/Store/Products/5-Practices-for-Orchestrating-Productive-Mathematics-Discussions,-2nd-edition-(Download)/). It’s about using Desmos to highlight and discuss student thinking and to uplift student brilliance. Although I’ve seen many, many presentions on the 5 practices over the year (especially at PCMI), this was a great reminder of a lot of the things I don’t know, and teacher moves I’ve stopped flexing.

The second was by Lauren B called “I am, We are, You are.” It highlighted a few things to me. First, there’s a gap between the demographics of people who teach mathematics (and their identities) and the population of students who learn math (and their identities). She posed a question (of which she thinks the answer is yes): “Is there a way to expand identity in a math class?” I think this is a great question to chew on — and not easy. Especially if you take away classes like statistics or data science from the mix. We played with a super engaging Desmos activity which gave us choice on which data sets to plot against each other, and the fun part was guessing what the scatter plot would look like before we saw it. And she had a quote from Rochelle Gutierrez (who I’ve met before briefly!) which I couldn’t copy down quickly enough, but went something like “Do I have to be a better you in this classroom, or can I be a better me?” This is a student asking the question — essentially saying “Do I have to mold myself to be a miniature version of you, the teacher, to succeed in this room we’re in together?” I also thought that had a lot to chew on… in terms of what we expect from students and the culture that we build together.

Okay, it’s now 9pm and I’ve been at this for way longer than I intended, so to sleep I go.
***
It’s the next day and the conference has finished and I wanted to archive — briefly — the remaining sessions.
First, Hollylynne L. gave the keynote talk “Data Science is Everywhere and For Everyone.” Some takeaways for me are that there are a few large organizations (like NCTM, NCSM, ASA, etc.) that are collaborating to create a united data science position. It’s drafted, and about to be adopted, and has four guiding principles: (1) data science is contextual and multidisciplinary, (2) data science is an investigative process, (3) data science understanding and experiences are for everyone, and (4) data science educators must develop and practice ethical uses of data. The presenter shared her experience ethnographically observing data scientists for 9 months and what traits they exhibited. Then she shared with us that she feels like data science needs to be presented to kids with larger data sets — in terms both of cases but also in number of attributes shared (e.g. not just a survey with one or two questions, but a survey that has a ton of questions!). As an expert on CODAP, she shared how to fluently use it to show data, ask questions, and then interrogate the data. That part was inspiring, and in only a few minutes showcased the power of CODAP (codap.concord.org). Her talk also got me thinking about how our department has over the years shoved all of data science/statistics to our AT Statistics courses as we were making room for everything else we need to teach. Lastly, at the end, she shared a resource I want to follow up on called InSTEP. It is a free online site [https://instepwithdata.org/public/] that is designed to get teachers ready to teach data science and statistics, and it sounds like you learn lots of content, pedagogical moves, and you learn to use various tech tools but primarily CODAP (which is what I want to learn). So yay!
My next session was by Reed H and was an invigorating conversation on Standards Based Grading. He presented a “post mortem” of him implementing SBG in his precalculus classroom for the first time, sharing why he made the switch but also the tradeoffs that occurred. Although our school is moving in a different direction, I was still curious to see how the SBG conversations were going — and it reminded me how much I liked SBG even though it took me 4 years until I had refined it to the point where I could run it fluidly in my standard calculus classes. Reed’s own observations, and the conversations we had as small and large groups, also reminded me of my own path to SBG, and how I now know there is no single flavor of SBG that is going to work for all, because its success is dependent on so many cultural and institutional factors. And there is no magic bullet that is going to make it suddenly easy.
My last session was by Verónica Z and Doru H and was on Linear Programming and Other Means of Optimization. The presenters shared three ways to do optimization without calculus. First, the standard linear programming. The second was something called the “simplex algorithm.” Honestly, I got very confused at this point, because it isn’t in any way intuitive and I think that part of the presentation was meant for people who knew the method. So I ended up stopping my notes and writing “very confused” on my page. (I did find this example that went through the algorithm that I’m curious to read though, to get the crux of the algorithm, but don’t think it will explain “why” it works.) Finally, we learned the TOPSIS algorithm which was just invented in 1991 (“Technique for Order of Preference by Similarity to Ideal Solution”). New math! And the presenter, Verónica, did a really cool job of showing us how to make a decision of which new phone to buy (out of a choice of three) if we were looking at two variables: picture quality and battery life. It’s such a simple algorithm that — at the highest level — has you develop two new “fake” phones that exist — the best phone and the worst phone — one with the best of the traits of the three phones that exist and one with the worst of the traits of the three phones that exist. We plot all three phones and the best “fake” phone and worst “fake” phone. And then we find the “distance” from each of the three phones to the best and worst “fake” phones, and use those distances to rank the phones. Details are in my notes, but I loved learning new math in the universe, and new math to me!
Lastly, the conference was raffling off math art, and although I didn’t win, a new friend did, and she saw how much I coveted them and offered me hers. I demurred and then eventually accepted.

***
Personal Note: Speakers for the most part shared their slides with attendees. So I’ve downloaded the sessions I went to and saved them on my google drive. But I don’t know if they are officially public, so I’m just linking to them here for my own easy access.