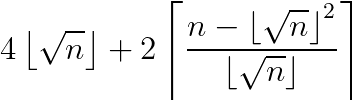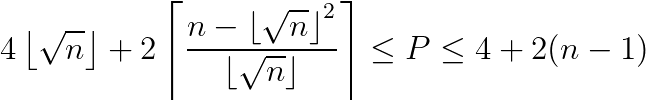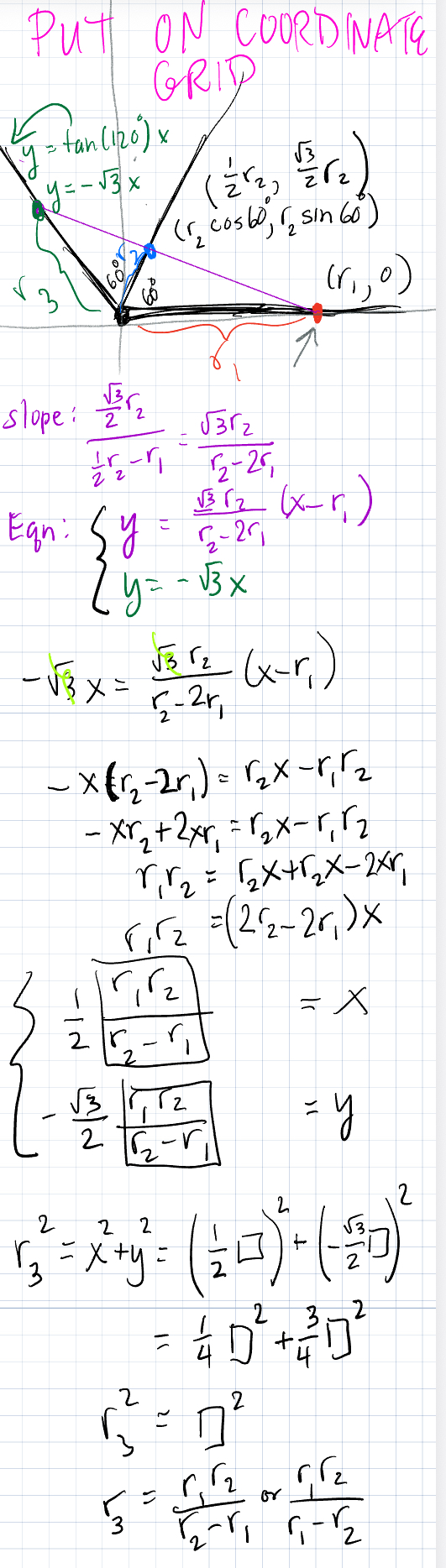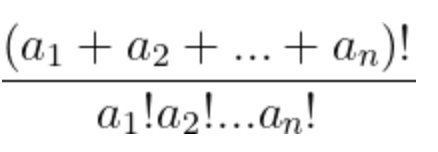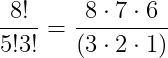A friend found this Sangaku, which if you don’t know (from Wikipedia) are Japanese geometrical problems or theorems on wooden tablets which were placed as offerings at Shinto shrines or Buddhist temples during the Edo period by members of all social classes.
The question that I’m attempting to figure out is: what is the radius of the small circle in relation to the length of the side of the square? And you’ll see from the text she sent me, there is the answer.
We found the puzzle curious and we thought the figure was lovely, so we decided to make a piece of stained glass math-art for it. (We’re trying to teach ourselves how to make math-based stained glass art. As you can see from the picture below, we’re still very much novices!)
I spent over an hour on the problem this morning. I played on Geogebra to get the contours of the problem itself to help me understand the constraints. And then since I didn’t have a better approach, I started brute forcing it. I came up with equations when I put everything on the coordinate plane (using calculus to find slopes!), found some tangent lines, and looked for intersection points of these lines. I knew it wasn’t efficient, but I thought it would at least help me see how things would shake out I was hoping lots of terms would drop away…
Alas! The algebra got messy, and then I thought I’d have a system of equations that could be solved.
To be frank, I’m pretty sure in the mess of algebra, these equations are probably not correct. And I couldn’t really solve them anyway. (If you’re wondering what a, b, and c are, they stand in for slopes of the three lines (pink, light blue, green).
I’m officially annoyed and ready to give up. At least for now, or for a few days, or maybe forever. BUT the reason I’m posting this is that I’d really love a solution. Why is the radius of the circle 4/33s (where s is the side length of the square)? What is the approach to figuring this out?
UPDATE: I posted about this online and here are some of the assists I’ve gotten. I was going to look at them today but I’m not feeling super well.
From Facebook: Bowen: “Check out Descartes’ Circle Theorem…” [here] From Jason: “I am sitting across from Bowen this morning and UNBEKNOWNST TO ME, you sniped us both in parallel. Unbelievable. I solved it on paper, got all excited, and then saw that Bowen– SITTING ACROSS FROM ME– has already supplies that link above. Anyway, I’m not going to let him Liebniz my Newton here. I did some work on paper independent of him and will publish it with pictures in the comments below.
I mean, I did not write the work in a way that was designed for other people to write, so there are a LOT of “S” letters that might either stand for “the numerical length of the side” or “the name of the solution circle”, depending on context.”
From BlueSky:
From diffgeom: If we invert the plane ((r,θ) -> (1/r,θ)) about the point where the three large circles meet, each maps to a coordinate line; the small circle maps to a circle whose center and radius look easy to find, and inverting again should give the radius? Will give this a try…
I replied: Omg- my brain!!! Wow! I don’t know if I’ve ever inverted the plane and I didn’t even think to look at this problem through polar. I’m so intrigued!!! Essentially you’re saying the diagram will look easier once we do the inversion, we find the answer in the inverted world, then put it back?
[At this point, I looked up and watched this amazing 27-minute Numberphile video that explains some of the basics of inversion and got me excited: https://www.youtube.com/watch?v=sG_6nlMZ8f4]
tcorica replied: So, I’ve captured everything in a Desmos sheet EXCEPT how to take the final circle and un-invert it to find the uninverted center and radius. Any hints? I’m avoiding “reading up” on inversion, but I will if needed!
P.S. I flipped the image across the horizontal so that the given circles had centered on an axis, making it easier to write the polar equations in terms of r. @samjshah.bsky.social
tcorica also shared: I saw the responses suggesting “inversion” – i.e. recasting the problem by writing equations r= and then rewriting them as r’=1/r=. I’ve still managed to avoid looking inversion up 🙂, but I’ve done some thinking and experimenting with it – it’s a surprising and cool technique. I’ve found a reasonably nice solution to this using inversion. Because the answer is a weird looking fraction, I’m wondering if perhaps there actually isn’t a pretty geometric solution to this pretty problem! As an introductory exercise, I found it useful to consider the problem of finding the intersection of the circle with radius P and center at (P,0) with the circle of radius Q and center at (0,Q). E.g., show that the POI lies on y=(P/Q)x. Tons of approaches possible, inversion being one. 3/3
diffgeom replied: My approach: A circle of radius r at distance R from the center of inversion has points at distance R±r on a ray; inverting in the unit circle gives points at distance 1/(R±r), so the radius is (1/2)(1/(R-r)-1/(R+r)), or r/(R^2-r^2). (IIRC, the distance to the center is half the sum, R/(R^2-r^2).)
nsato7 also commented after diffgeom:
As @diffgeom.bsky.social points out, inversion takes care of the problem nicely. (And many of these Sangaku problems were solved by inversion.)
The three arcs invert to three lines. There are two circles that are tangent to these three lines; we want the “top” one.
mqb2766 shared: Similar to the other posts, a modern version of this problem is gps/trilateration with the distances from the known centers being 2-r and 1+/-r so 3 quadratics in 3 unknowns – the center and the radius. You get a trivial solution of r=0 as well as the stated one.
noswald also shared (unrelated to the others): My inelegant solution would be to impose a coordinate system on the figure and set up three equations involving the coordinates of the inscribed circle and its radius. We know the distance from the center of the circle to a corner is s-r, to one side’s midpoint is s/2-r, and to another side is s/2+r
From Email
My friend Japheth W sent me his written work, which he said I could archive here, noting “It’s not quite publication ready, but probably understandable to math teachers who are experts at reading even more disorganized student work.”
Like in my last post, I want to share a math problem I was working on for a summer professional development I’m doing. This was part of the problem set that the PD organizer Justin Lanier wrote up. The problem is outlined here:
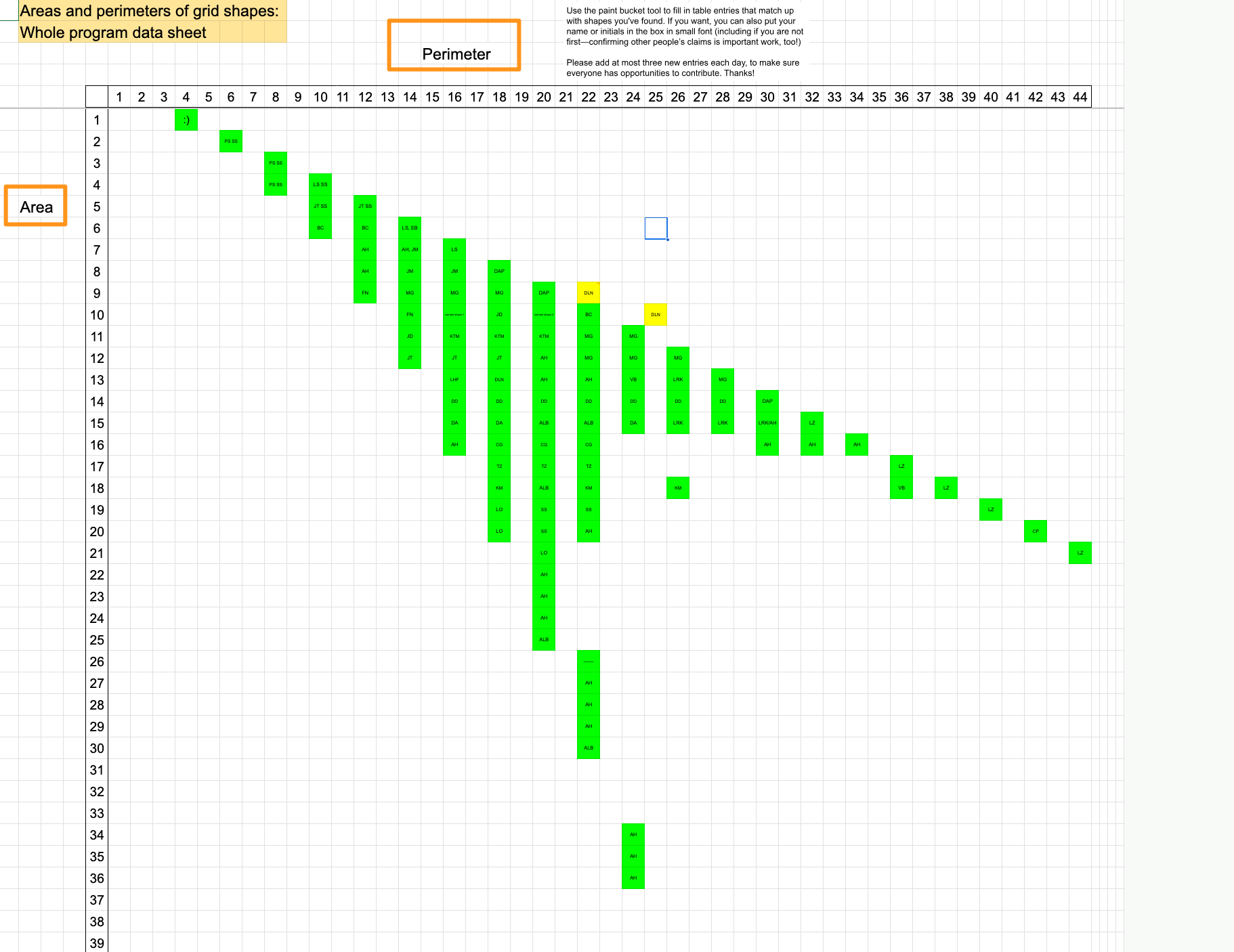
As part of this professional development, we started filling in a spreadsheet with various areas- perimeter combinations we could create. This is a screenshot of collaborative sheet we came up with:
I played around with this problem for hours and hours. I decided I wanted to focus on this question: If you have a given Area of n, what is the MaximumPerimeter you could get, and what is the MinimumPerimeter you could get?
I was relatively easily able to prove that for an Area of n, that the MaximumPerimeter you could create is 4+2(n-1). Here’s the argument in a nutshell. Each time you add on a new square to an existing figure, you either are adding 0 to the perimeter, 1 to the perimeter, or 2 to the perimeter. (This is easy to show.) So to get the MaxmimumPerimeter, you want to be adding the most to the perimeter each time. So if you start out with a single square (n=1) with a perimeter of 4, each time you add a square, you’re adding at most a perimeter of 2 to the figure. One easy way to create this figure is to just add squares like this:
This is where the 4+2(n-1) comes from. You start with a perimeter of 4, and add 2 every new square you add to it.
It took me a while to figure out the MinimumPerimeter. I am pretty certain I have it, but I’m still working on proving it in an airtight way.
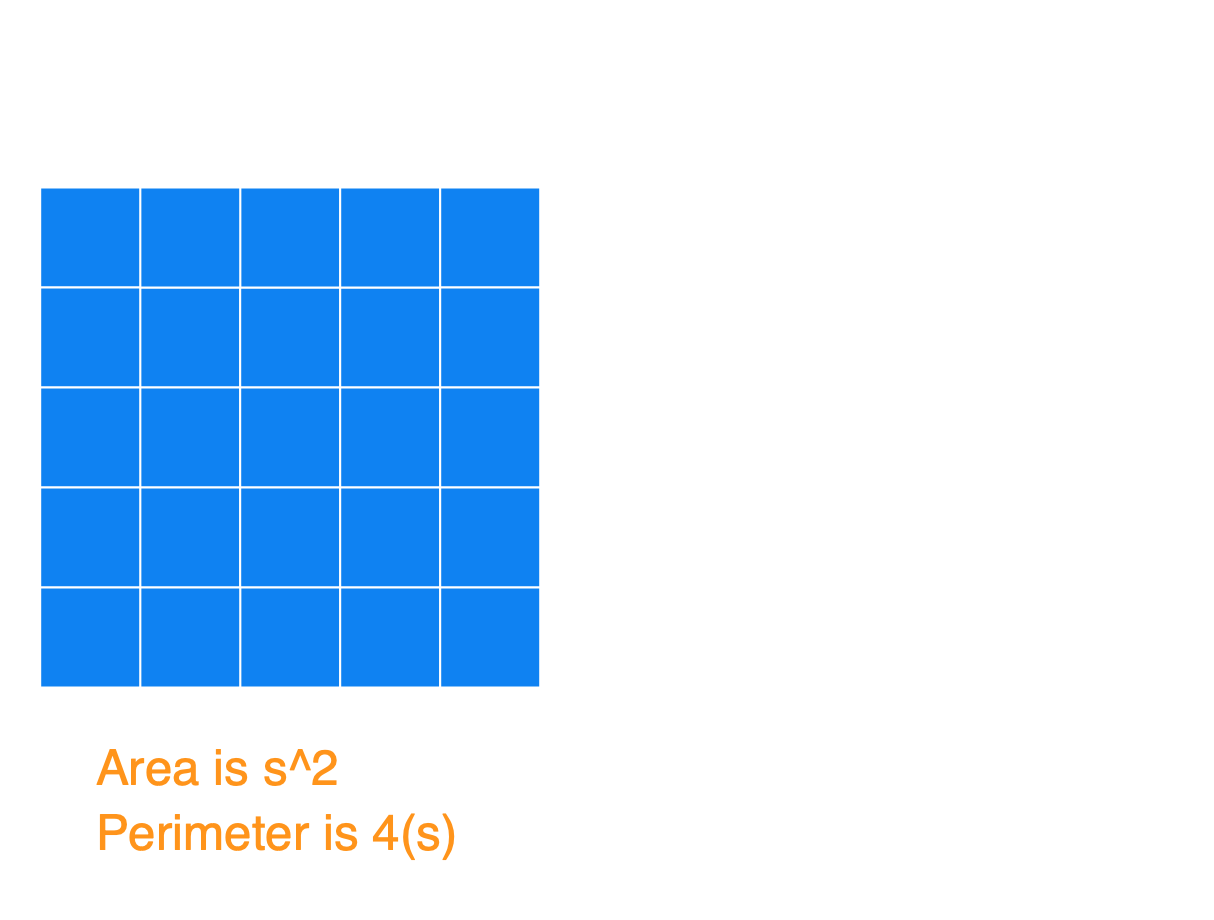
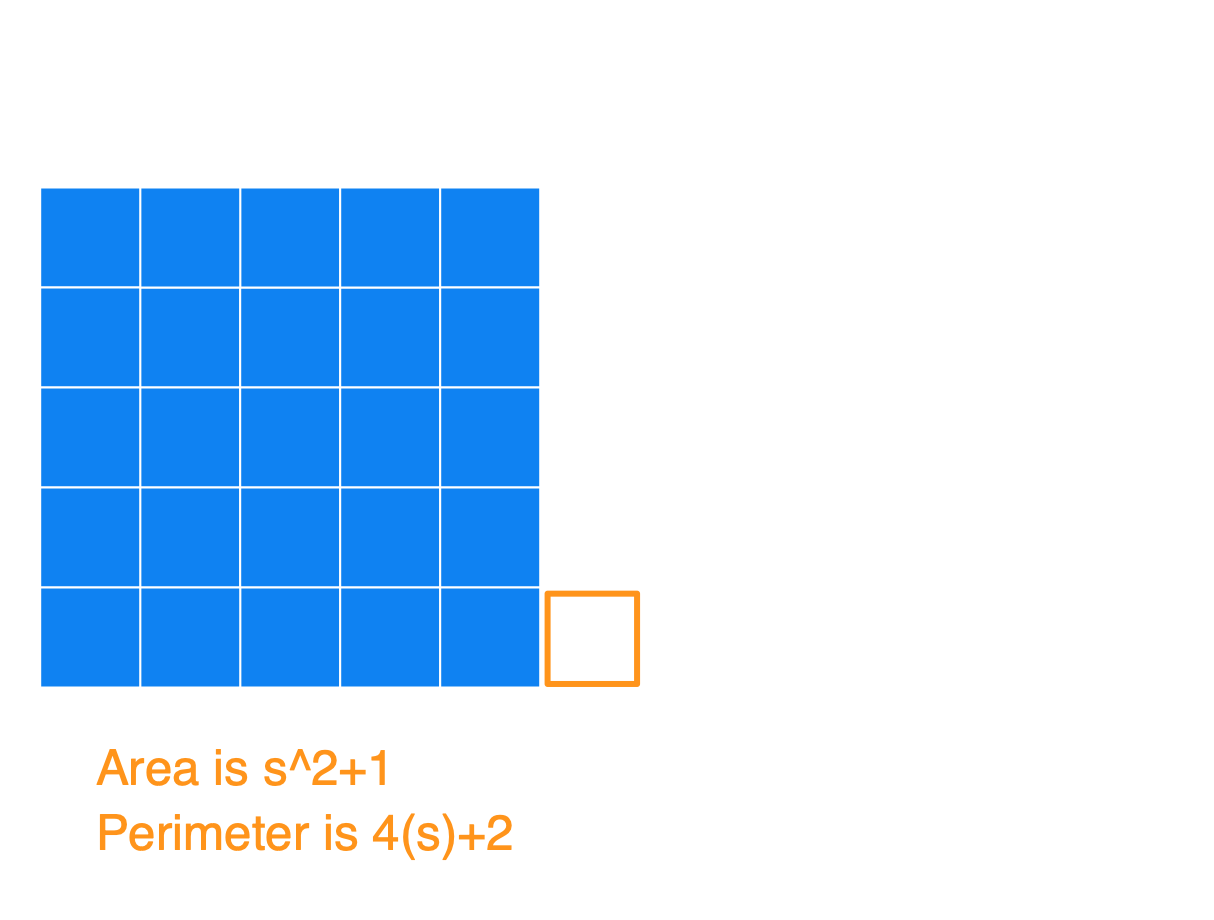
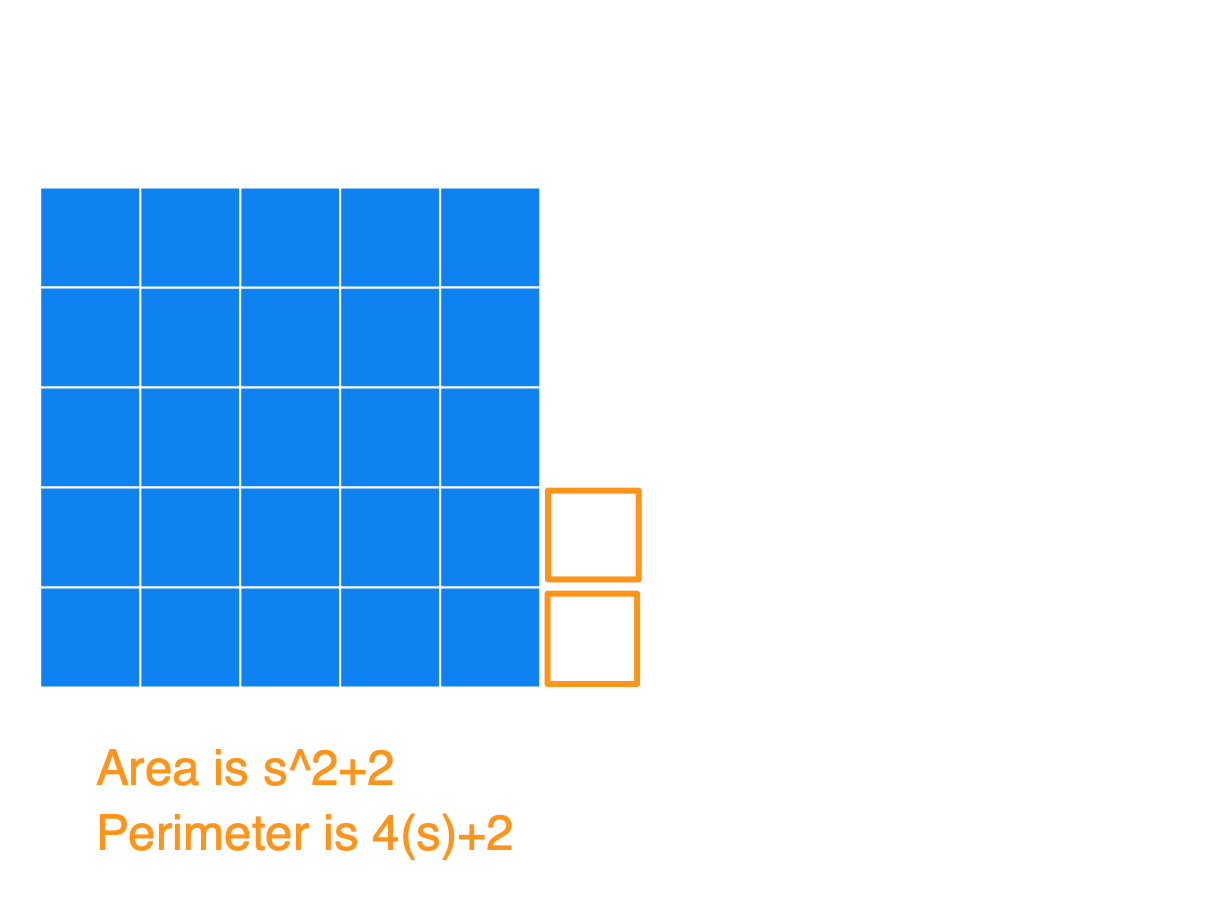
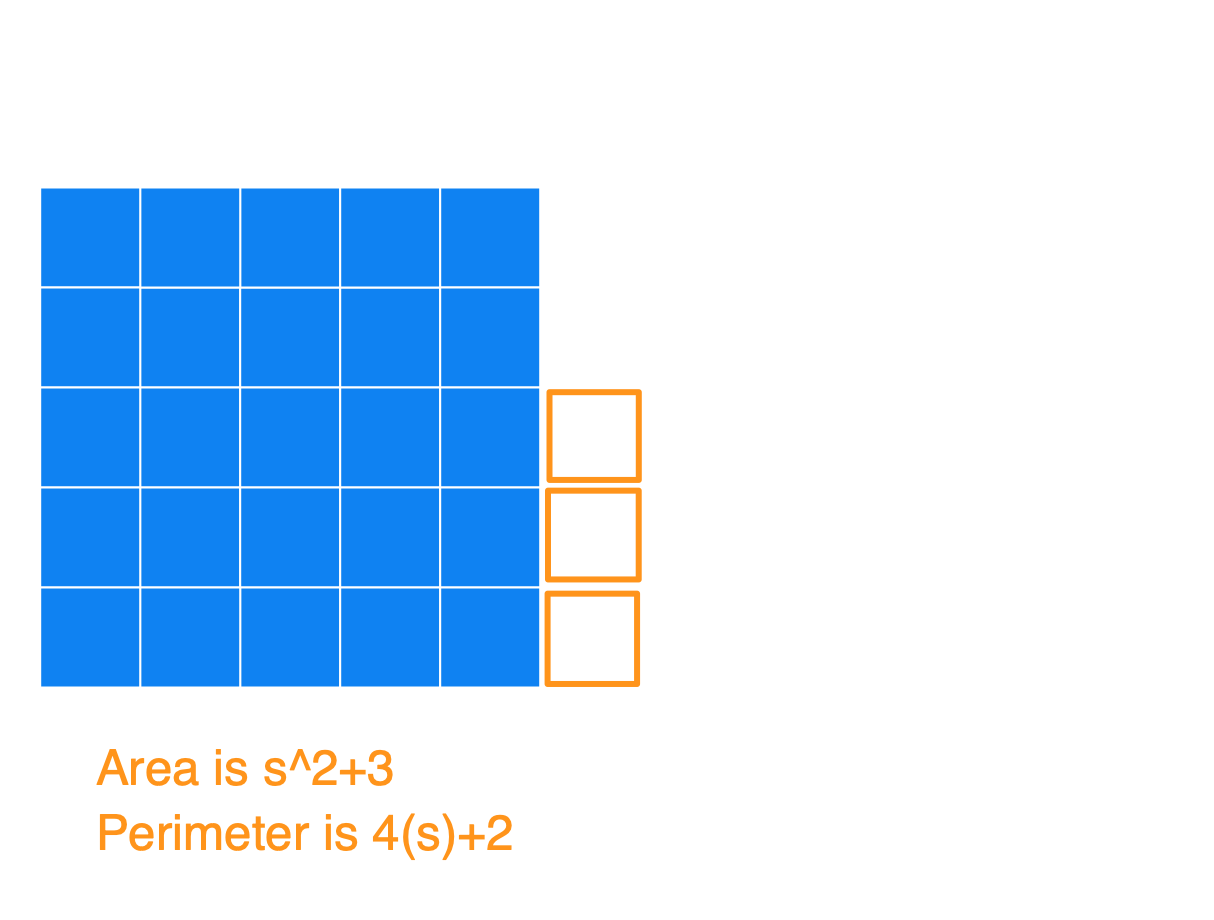
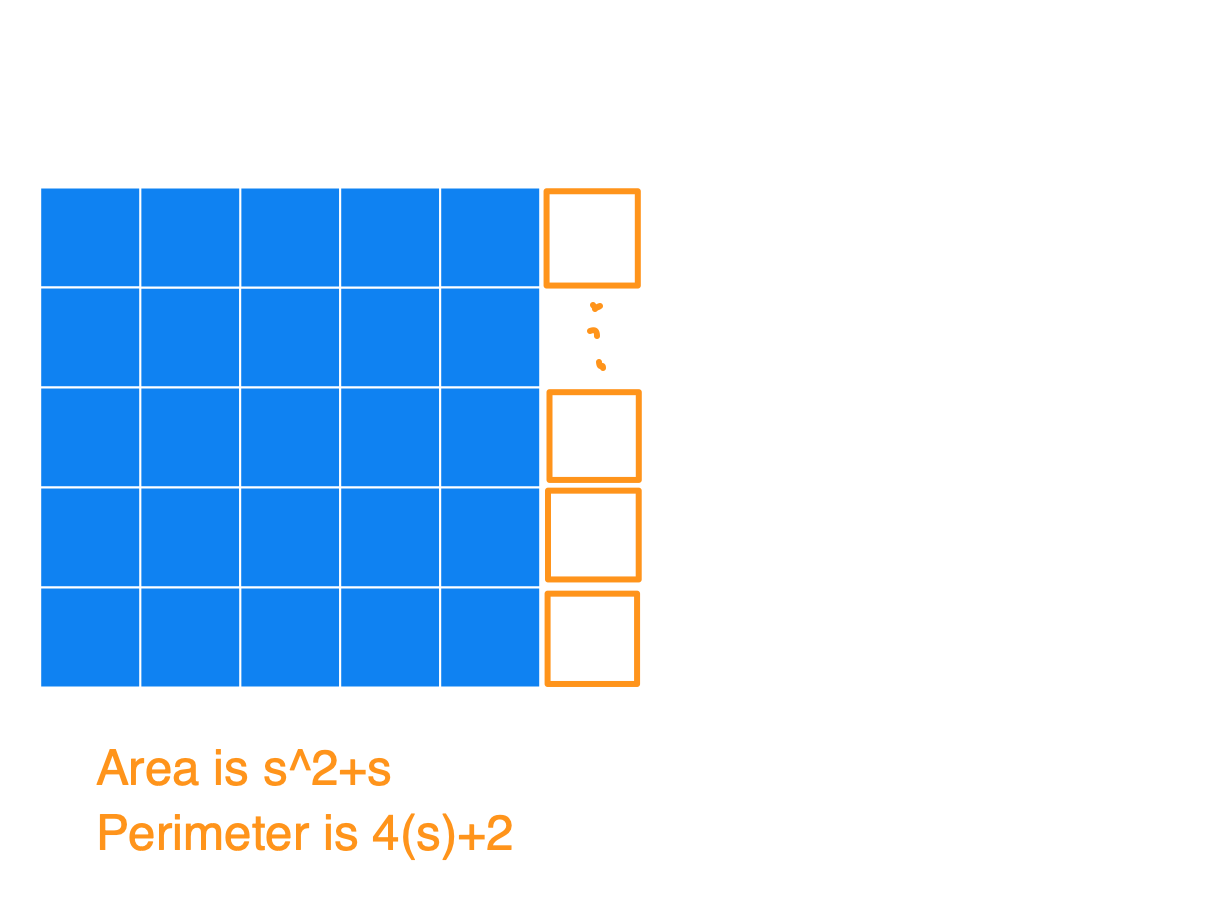
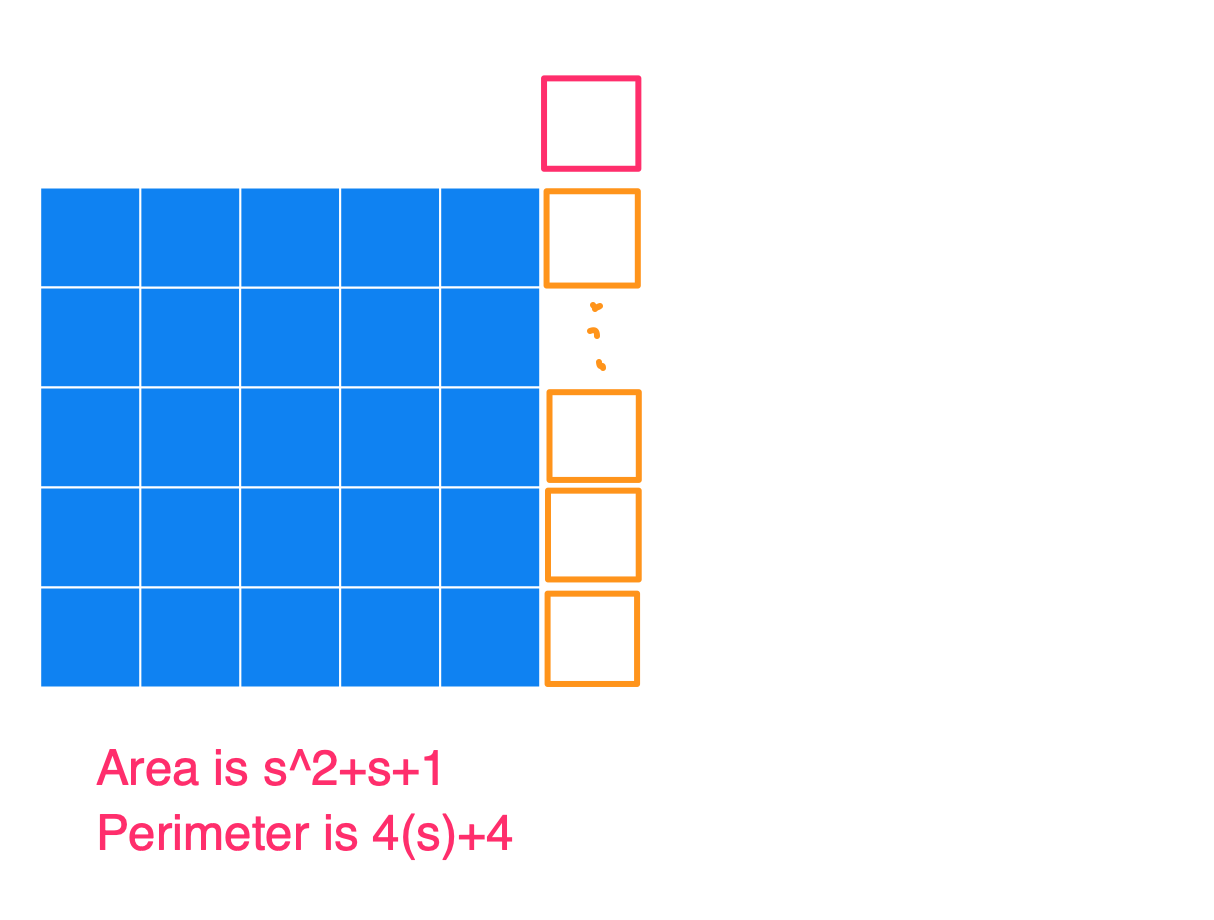
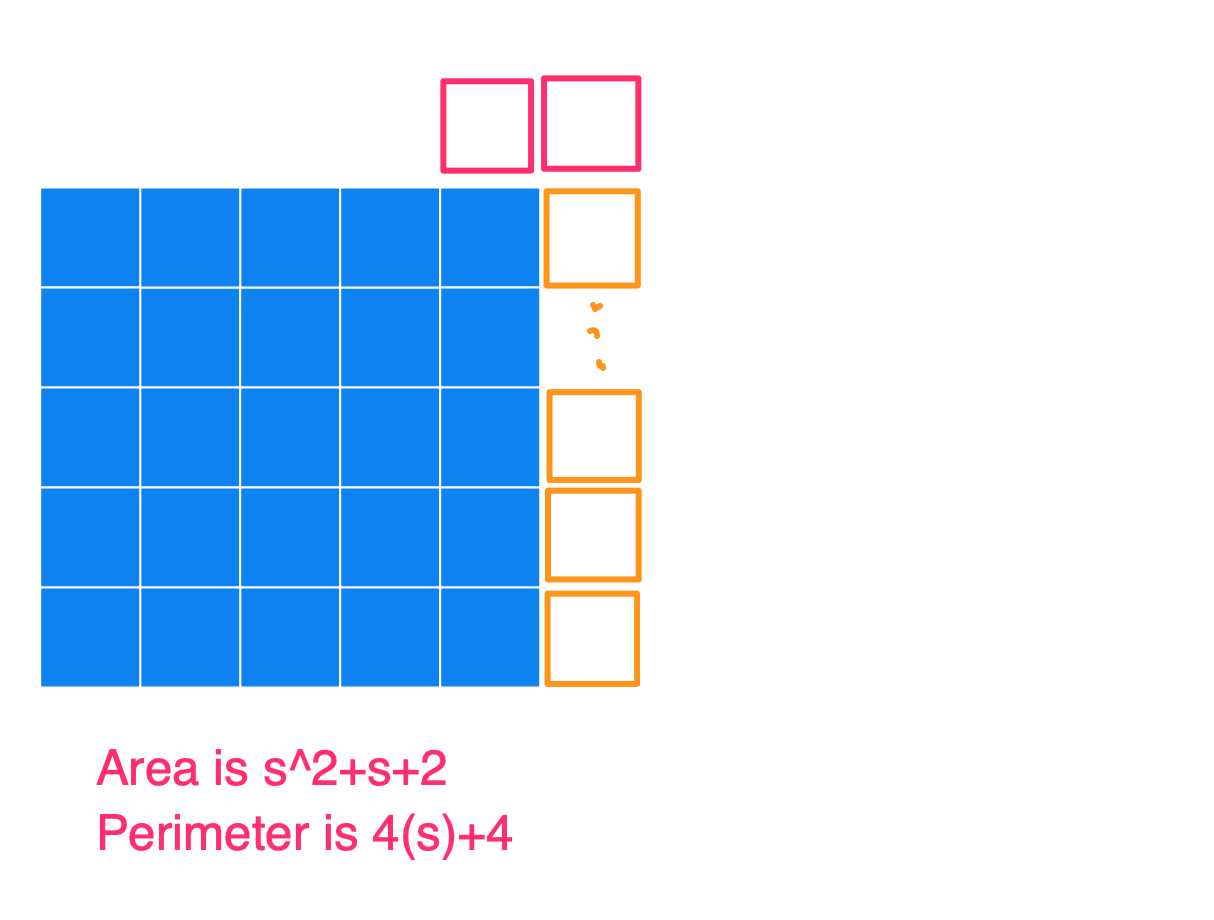
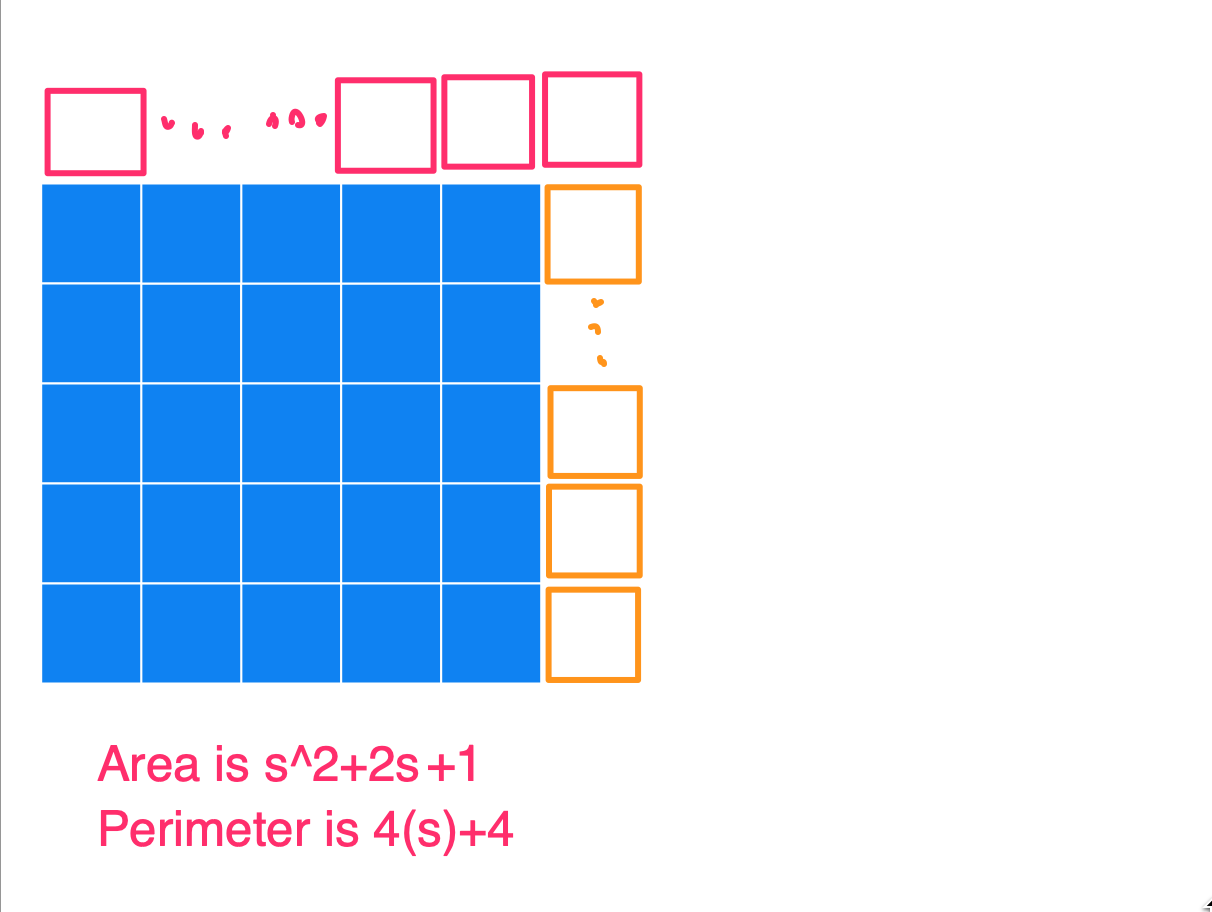
Basically, the way to construct the figure with a minimum perimeter is to create the largest square you can, and then append the remaining blocks to it. Below I have a series of images to show what the figures could look like for an Area of 25, 26, 27, …, 36, and also the Perimeters. I used s in the image (instead of 5) to show how this generalizes for any square number.
Some observations:
(1) Notice that after you start with that perfect blue square, each time you add a square (so for an area of s^2+[1, 2, 3, …, s]) you’ll always get the same perimeter of 4s+2. At this point, you’ll have an s by (s+1) rectangle.
And then when you continue on adding more squares to this rectangle (so for an area of s^2+[(s+1), (s+2), (s+3), … (2s+1)]), you’ll always get the same perimeter of 4s+4.
(2) At the end, when you’ve finished this process, you’ll have a new area of s^2+2s+1, which simplifies to (s+1)^2. And the perimeter of this is 4 times the side length of the square, which is now s+1. So this makes sense as 4s+4.
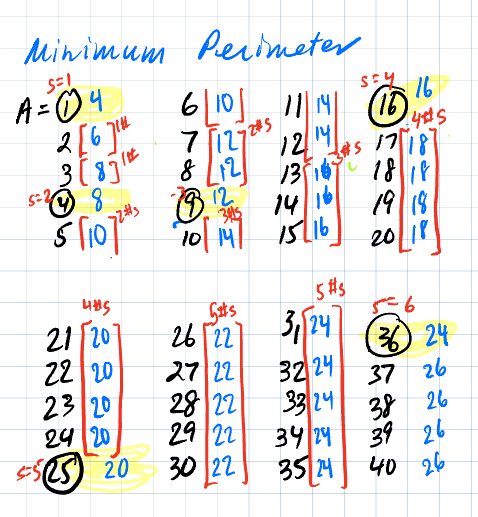
Here’s a chart I made which shows how the perimeter goes up after you hit perfect squares… Notice we know the perimeters of perfect squares, so for example at A=16 (a 4 by 4 square), the next four numbers will have a perimeter of 18 and the four numbers after that will have a perimeter of 20. That’s then when we hit the next perfect square of A=25.
So far, we have this:
Take your Area of n and find the largest perfect square the goes into it. Call that s. If the remainder is 0, then you have a minimum perimeter of 4s+0. If the remainder is 1, 2, 3, …, s, then you have a minimum perimeter of 4s+2.If the remainder is (s+1), (s+2), (s+3), …, (2s), then you have a minimum perimeter of 4s+4
However I didn’t want a formula in terms of s. I wanted an explicit and closed formula in terms of n. I wanted a direct answer to the question: if you have an Area of n, what is the Minimum Perimeter in terms of n? And I got it…
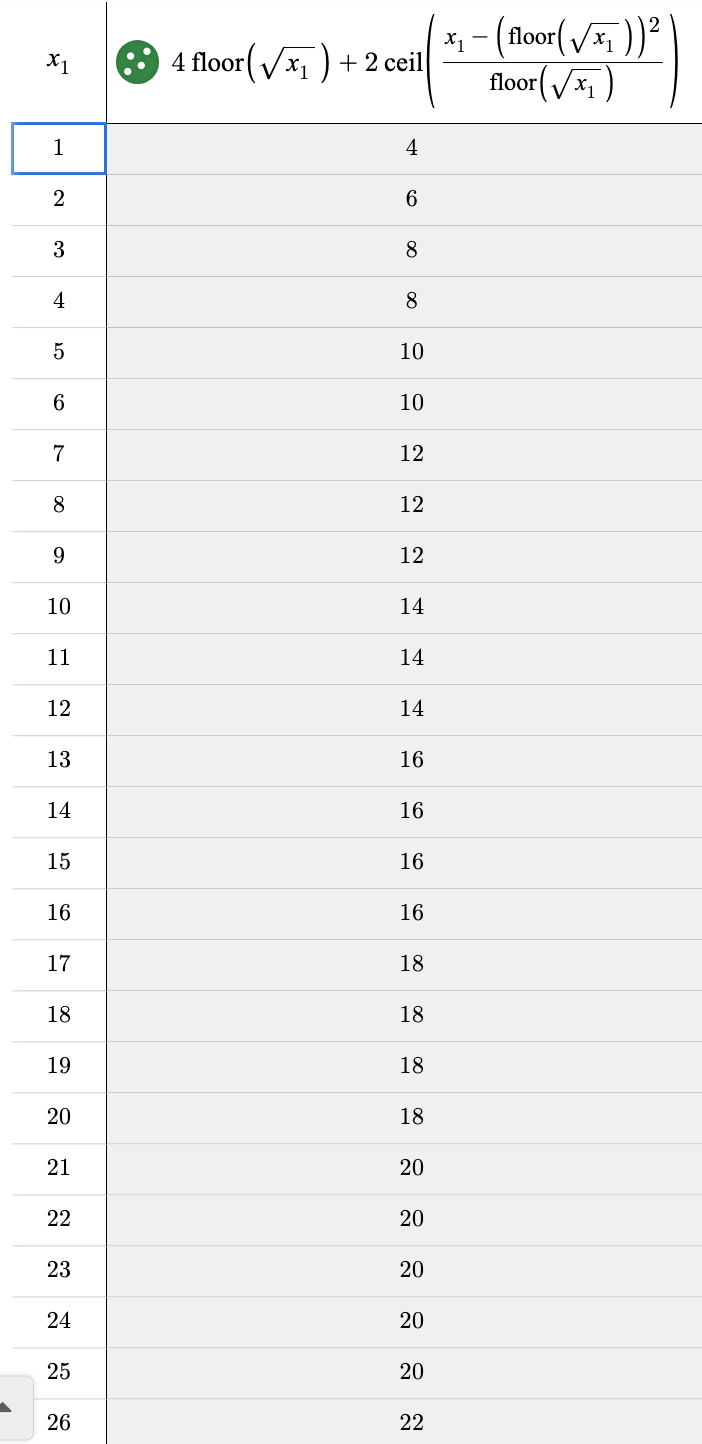
It’s kind of ugly looking, but hopefully you can see the motivation. The first part is just 4s. The second part is the correction factor (of +0, +2, or +4). The numerator in the ceiling function calculates the remainder. When you look at the entire ceiling function*2, it will give you 0 when you have a reminder of 0. It will give you 2 when you have a reminder of 1, 2, 3, … , s. And it will give you 4 when you have a remainder of (s+1), (s+2), (s+3), …, (2s). I was pretty proud when I was able to use my table above to figure this out. I checked using Desmos to confirm!
At this point, I’m confident about these bounds for the Perimeter of a figure with Area n…
Now I’m stuck on the very last thing… I am confident with my formula for the Minimum Perimeter, but I haven’t proved it.
I think I have a way to show that if the Area is a perfect square (so n^2), then the Minimum Perimeter always occurs when the squares are arranged to form an n by n square. However at the moment I can’t seem to move forward from there.
This is going to be a writeup for a math problem I’ve been working on for a professional development thing I’m doing this summer. The question related to soap bubbles. Because I just want to get something up, for now I’m going to quickly say that the problem I’ve been tackling reduces to this:
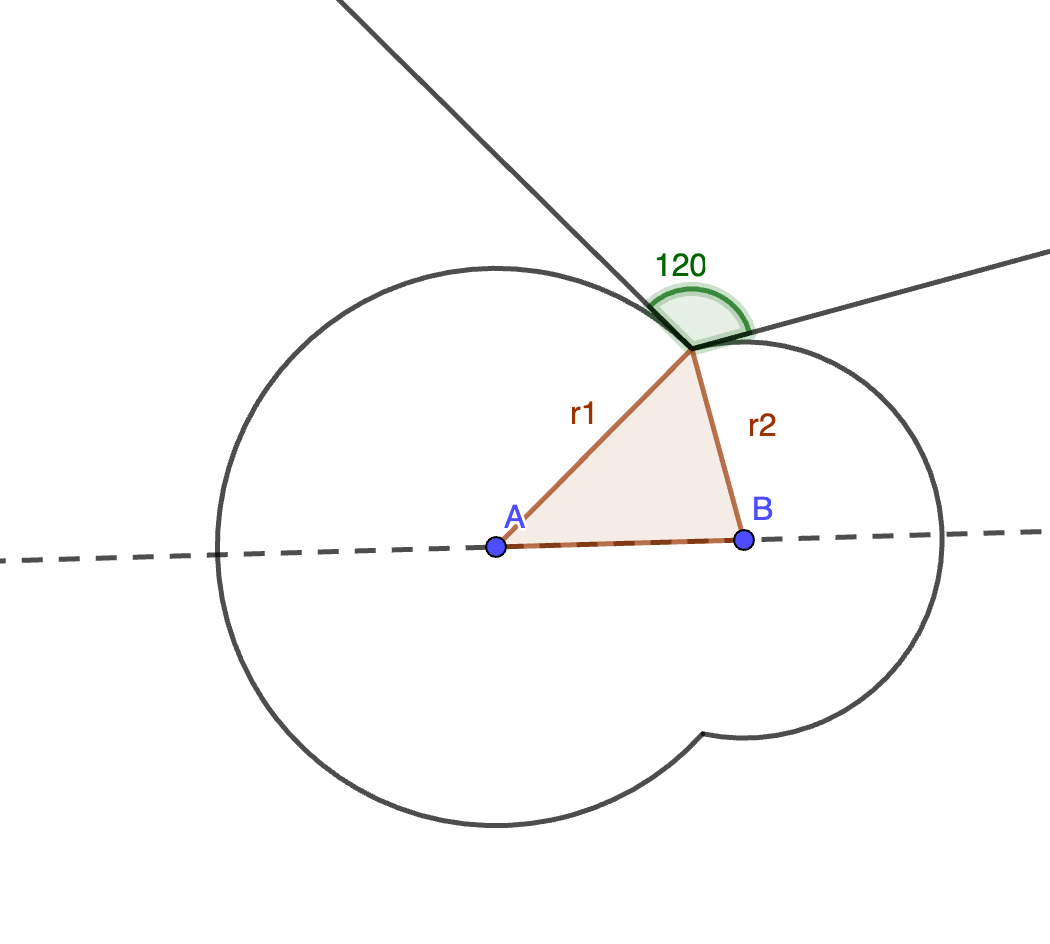
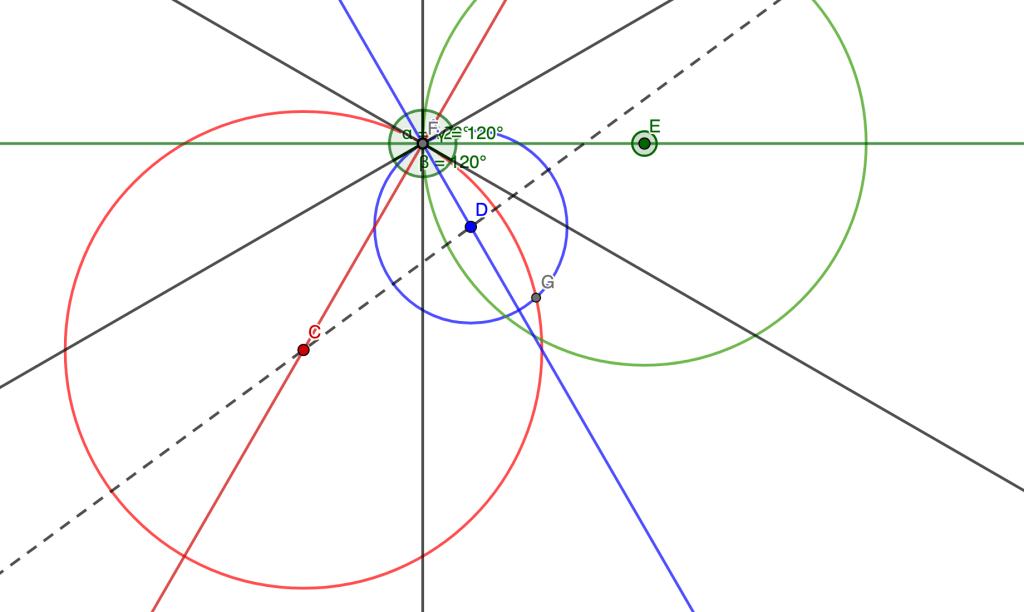
Let’s say I have two circles that “intersect at 120 degrees” like in this diagram below (if you zoom in enough at to the intersection point of the circles, the two circular lines are approximated by the tangent lines I drew, and the tangent lines form 120 degrees to each other):
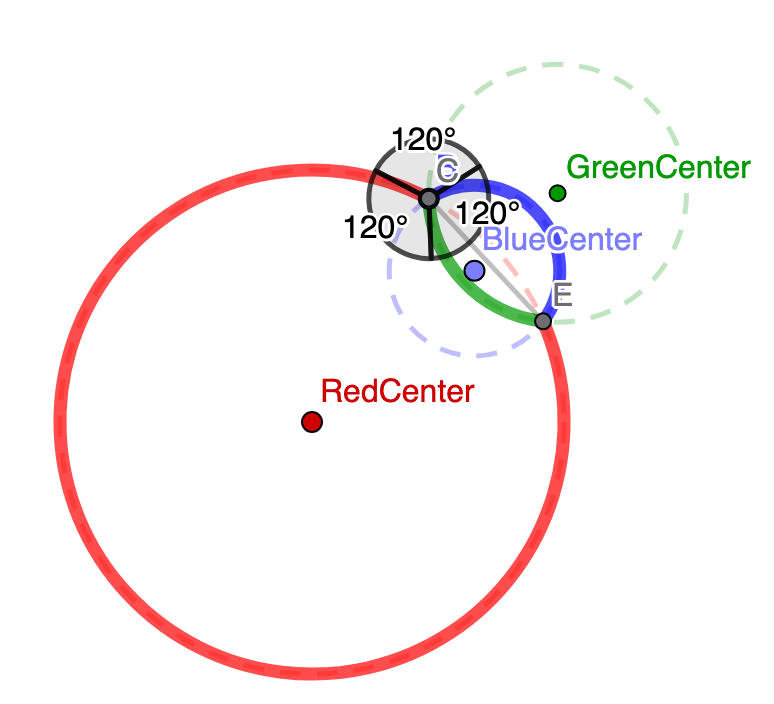
It turns out that there is a THIRD circle which can also intersect with these two circles and form 120 degree angles. Here are some different configurations that showcase this.
The question I’ve been dealing with is this: given the two initial circle radii (the red circle and blue circle, in the pictures above), can I come up with a formula for the radius of the third (green) circle?
I’ve been working for a few days to find the answer. I felt at times I was going in circles (no pun intended), and indeed I was. When I got the answer, I was astounded.
It was much more elegant than I anticipated! Everything simplified in a beautiful way. And my work was so ugly… I mean, I was using the Law of Sines and the Law of Cosines and the sum of angles formula for sine… so after taking a break from the problem, I went back to see if I could do it much more simply, now that I had played around with the problem and better understood the contours of it. I could!
First, I had to show that the angle formed by the radii to the intersection point had to be 60 degrees.
Here’s my work for that, using the fact that the tangent lines to the circles form right angles with the radii.
I next added in the third circle into the picture. Here’s a very not-pretty applet I made [https://www.geogebra.org/classic/wysfbqwn]. Drag point E and see what happens… I’m getting all possible green circles that intersect the red and blue circles at 120 degrees. There are an infinite number of them!
If you just want to see the picture, click through the images below to see what happens as I change the radius of the green circle to gradually bigger and bigger and bigger.
There are an infinite number of green circles that work! However, only one of the green circles also intersects at point G, the other location where the red and blue circles also intersect. So that’s the green circle we want. It took me a hot second to reason out why point E has the lie on the same line as C and D. I’m just trying to get this posted, so I’ll add that reasoning in later if I have time.
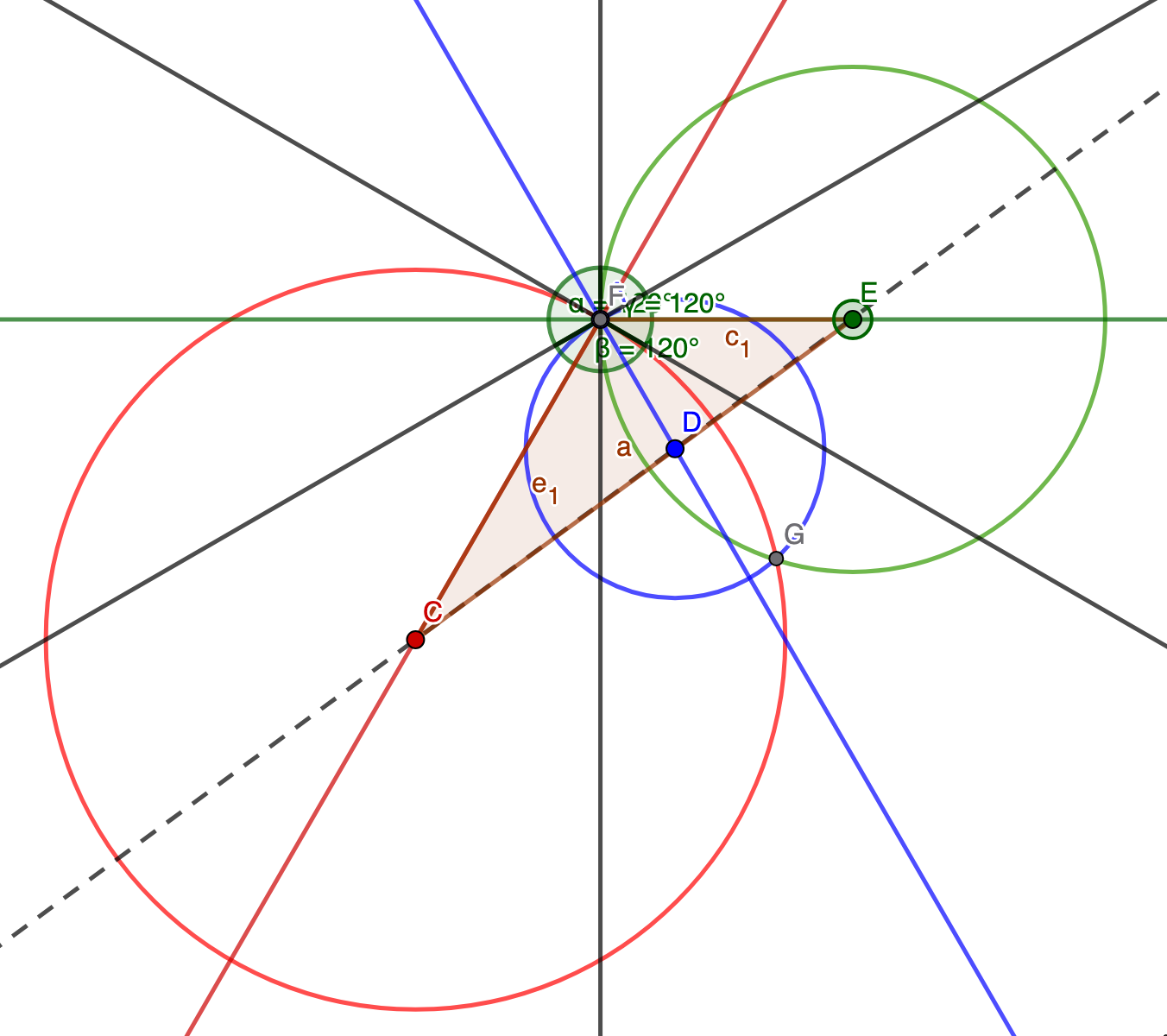
At this point, for me, the problem involves focusing on the triangle highlighted below:
I’m going to look just at the triangle now. We showed that the angle between r1 and r2 is 60 degrees. An identical argument can be used to show that the angle between r2 and r3 is also 60 degrees.
To keep things straight in my head, I highlighted the things we know in yellow. We are given r1 and r2, and we know the two angles are 60 degrees. We just have to find r3, which is the radius of the third green circle!
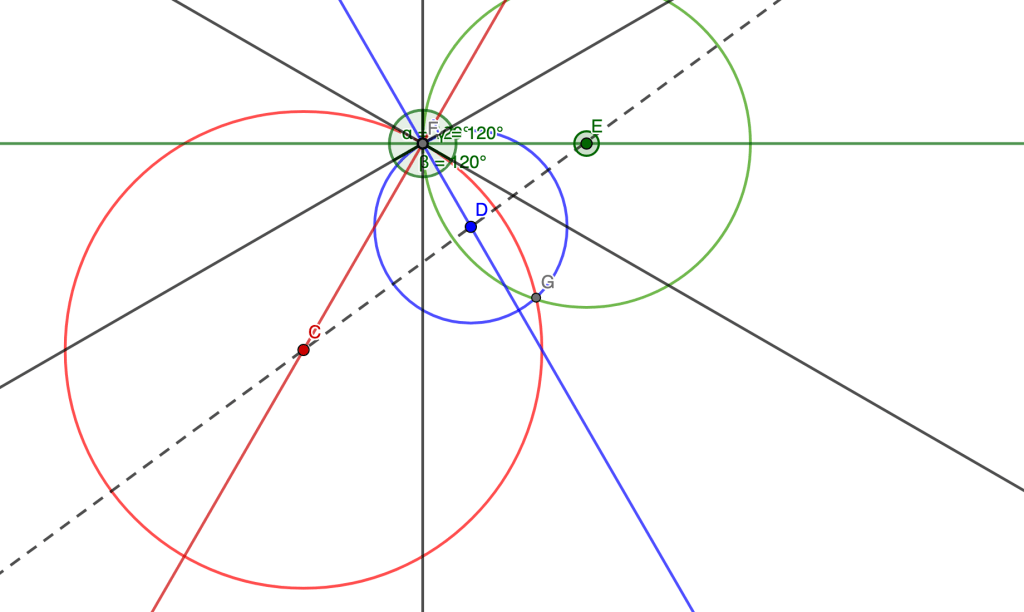
At this point, I think there are lots of things one can do. In my original work, I was using lots of Law of Sines and Law of Cosines. But in my revised work, I didn’t need any of those things. I decided to rotate the triangle.
And the reason I did this is to put everything on a coordinate grid. From here on out, my work just fell out nicely! On the diagram below, I found the equation of the purple line. And then I wrote the equation of the line that forms r3 (what I’ll call the green line). And then I found the intersection point of the purple and green lines (the green point). And then I found the distance from the origin to the green point.
And that formula below is precisely what I found in my messy, convoluted first attempt that took hours and wasn’t as elegant.
Writing this formula in reciprocal form, we get either the first or second formula:
I remember from when I taught multivariable calculus that the measure of curvature of a circle is the reciprocal of the radius. So in that formulation, the curvature of the third circle is the difference in curvature of the other two circles.
In my last post, I shared a question posed to me by a student. Essentially, it boiled down to: can we algebraically prove that the following will always be an integer?
I shared it with two friends in my department because they both really love combinatorics like me. One gave me some really nice ways to think about it and set me upon a nice path forward. But before I could go there, the other (the illustrious James Cleveland-Tran) shared with me his thinking. It was amazing. I wrote in my last post I love when things I can’t explain (in mathematics) feel like magic, because it means I get to learn something cool to figure out what makes it work. And when I do, when I understand something so well that the magic suddenly feels mundane (I think I used the word “obvious”), that is a wonderful moment. Because that means I fully grasp something. As James shared his thinking with me, I had that moment. Of course this had to be true. It doesn’t involve anything so deep I had to work to get it. It felt simple, and simply put, beautiful. I’m going to share that reasoning here.
So to start, I want to remind y’all that the things being factorialized and multiplied in the denominator all add up to the numerator. I am going to use a specific example to illustrate this and work through the ideas:
The whole proof hinges on this idea: a product of n consecutive integers will be divisible by n! Since James showed me this, I’ll refer to this as the James’ Theorem.
So let’s look at this example more closely. I’m going to expand out the numerator.
Now I’m going to group the numerator into groups of consecutive integers. Of course you can see we can do this in different ways. Here are some of them!
By James’ Theorem, we know the three consecutive blue numbers in the top of the fraction will evenly divide the 3! in the bottom of the fraction, the four consecutive red numbers in the fraction will evenly divide the 4! in the bottom of the fraction, and the five consecutive yellow numbers will evenly divide the 5! in the bottom of the fraction. And thus we’re done.
Now how do we know James’ Theorem is true?
Okay, I officially hate my life. GOSHDARNIT ALL TO HECK! As I was typing up the rest of this post, showcasing what I thought was a wonderful, deep, clear understanding of something that felt so obvious, I realized I don’t understand it fully. ACK!
And so, again, I’m in the realm of magic again. This isn’t the first time. This happens to me a lot with really interesting problems. I almost always discover a mistake in my reasoning when trying to write up an explanation with simplicity but also being comprehensive. And that’s exactly what happened here. (This is one reason why explaining my reasoning clearly to others is so important in my math process, and why I love kids talking about their mathematical thinking with others! It forces critical self-reflection.)
So here’s where we’re at. I do fully accept that if James’ Theorem is true, then we’re done! But I had a misconception that makes me feel a little embarrassed looking back at things.
I was thinking for each consecutive 5 integers, for example, had one of those integers divisible by 5, a different one had one of those integers divisible by 4, a different one had one of those integers divisible by 3, a different one had one of those divisible by 2, and the last remaining one had one divisible by 1.
Like I’m illustrating here:
But… yeah… that’s not always the case… Here’s the text I sent my friend James…
I’m now wondering about the factorial proof. I agree that if we know that the product of k consecutive integers were divisible by k!, the proof is done. But it’s not obvious to me anymore.
If we have the five numbers 27, 28, 29, 30, 31, I had convinced myself that one was divisible by 5, a different one was divisible by 4, a different one was divisible by 3, a different one was divisible by 2, and the last one was divisible by one. In my mind they had to be different ones. But that doesn’t work here.
And I thought they had to be different because in this case for example when they’re not, you then have to show after you divide one number out you might have to then divide a second number out and I don’t know why the second division necessarily works. Like in this example… after dividing out the 5 and the 4 and the 3… the 2 would have to divide into the 30 or 28. But the 28 already had 4 divided out so it wouldn’t be able to be divisible by 2 (what you’re left with is 7). And it feels magical that the 30, after being divided out by 5, happens to still then be divisible by 2.
In other words, how do I know the 2 will still be able to be divided into the 30 or 28?!?
Of course, I know with this specific example it can divide into the 30 (even after the 5 divides into the 30)… but how do I know if I did this with another set of n consecutive numbers, I wouldn’t hit a place where after you’ve divided out a bunch of numbers, you’re left with a number in the denominator that won’t go into the numerator?
Here’s my current state of things. I believe James’ Theorem and know it will unlock this problem. But I don’t get with any depth why it’s true. So I’m super happy that the original question posed by my student has been reduced to something “smaller.” I also think I might be at the point of wanting to google this to see what I can discover. I am still going to hold off for a bit longer, but I’m not sure how much longer.
Today in class, a student asked a question that stumped me. I haven’t yet given myself a lot of time to think about it, but I went into the city after school for something and on the subway ride home I had my audiobook on and I basically didn’t “hear” anything because my mind kept wandering back to this problem. (Ack! Now I have to rewind like 30 minutes of it.) And so I wanted to share it with you in case you wanted to work on it. Feel free to throw your thoughts in the comments.
We’re studying combinatorics (the art of counting) in precalculus. And we were seeing things like
pop up as answers to counting questions. And each of these evaluates to an integer.
The student asked: “BUT WHY? Why do these happen to evaluate to an integer?”
To give credit to what we’ve been doing in class, we spent about 3-4 days building up a deep conceptual understanding of why these would be the answers to particular counting scenarios, starting with first principles [1]. And we knew, since they were answers to counting problems, and that the number of outcomes to our given scenarios had to be an integer, that these had to evaluate to an integer. I would argue we have formally proved using a conceptual argument they had to turn out to be an integer. I think this is quite elegant! So on a mathematical level, we’re done. We’ve proved it.
However I liked this question a lot because I remember having it myself when I was in high school. And when I was teaching combinatorics for the first time. And randomly every so often since. I absolutely am certain I have thought about this before, and I also am certain I have no memory if I ever answered the question for myself or not. (My mind is like a goldfish.
So I pose it to y’all. On apurely algebraic level, how can we prove the following will be an integer:
Or I’d be okay with an even simpler version: how could we prove (again, purely algebraically, or with number theory, but with no reference to combinatorics) that the following will be an integer:
It’s harder than it looks, at least for me upon initial glance. I mean, I’m me, and needed to ground myself, so I started with a concrete example:
And I did the “canceling” and I saw we have some stuff that happens to divide evenly…
Yay, we see the 6 in the numerator divides out with the 3 and 2 (or the 6 divides out the 3… and 8 divides out the 2). But it feels like happenstance. And the more I wrote up examples, and I saw random things divide out from the denominator into various numbers in the numerator without rhyme or reason, the more happenstansical it all felt. It didn’t leave me to the next step in a proof…
The more examples I did in this very concrete and simplistic way, the more magical it felt. That I could find the right numbers in the numerator to cancel out with the numbers in the denominator — and still be left with an integer at the end! I loved the feeling of magic in math, because it means there’s something that is happening that I don’t understand, that’s ripe to be mined! And the moment I make something magical into something “obvious,” that’s when I know I’ve fully understood something. Right now, I’m in the magical phase.
In any case, I was thinking maybe I need to move forward with a proof by contradiction… or even induction?
I’m not sure if any of this made sense. But if it did, I’d love any thoughts in the comments!
[1] I have a very unique way of introducing combinatorics. At some point I should blog about it! But it basically reduces many, many combinatorial problems to the same type of problem. By the end of our unit, students don’t see “combinations” and “permutations” as different things that are related to each other. We zoom out and end up seeing them as the same thing. And moreso, my approach even lets them solve more complicated problems that combinations and permutations can become a bit more challenging to use. :)
On Thursday, after school, I hopped in an Uber to the airport. I was flying to a conference, the “Teaching Contemporary Mathematics” conference (TCM) held at the North Carolina School of Science and Mathematics. I think I’ve been at least twice over my career, maybe three times, and always found it to be a really solid conference. The big sell for me is that it’s primarily high school math-focused, and most of the sessions are given by actual math teachers about their own teaching practice. And more importantly, it’s felt like forever since I just got to geek out with other math teachers. A fellow teacher from my school and I arrived pretty late and just passed out, with dreams of conference day on Friday.
Although I haven’t blogged in forever, I wanted to at least outline a few things tonight that I can return to. But it’s late and I’m tired, so I’m only going to do a few tidbits.
There were two sessions that got the mathematical side of my brain whirring.
Ryan P gave a talk on “A Rainbow of Random Digits,” where he went from 1D to 2D to 3D to think about a interesting problem. I thought what he showed was beautiful, especially for the 1D and 2D which I could see using with students in a sort of ongoing independent study/investigation. For the 1D question, he asked us if we had two dowels, of length 1 and length 2, and we split the larger dowel into two pieces, what is the probability that the (now three) dowels could form a triangle. A nice fun introductory question with various approaches to answering it. For the 2D question, he asked as a warm up: if you had two numbers chosen randomly between 0 and 1, (a) what is the probability that the sum is greater than the product, and (b) what is the probability that the sum of between 5 and 6? Lovely scaffolding, and the first question requires a little bit of calculus, which is fun. And then the full 2D question (which can be answered using some calculus, but I think it’s even more beautiful without it): if you have two random numbers between 0 and 1, what is the probability that the first non-zero digit of their ratio is a 1? a 2? 3?… 9? Totally fascinating 2D probability space, with lots of “triangle slivers.” To whet your appetite, here it is:
And totally not my intution, but the probability of getting a 1 (33.3%) is greater than the probability of getting a 2 (14.9%) which is greater than the probability of getting a 3 (10.2%), etc. The calculation involves some fun infinite geometric series. All of this was new to me. I also have no idea why getting a 1 digit is more likely than getting a 2 digit which is more likely than getting a 3 digit, etc. My intuition–which was way off–made me think all digits would be equally likely. Now honestly, I don’t know how teachers can actually build something like this problem into their normal classroom practice, but I do know that I’d love to work with a student to get them from the statement of the question to the answer in a lovely set of independent investigations, and some well-thought-out hints to guide. (And maybe chatgpt to write some simple code to do an initial simulation.) My friend and colleague suggested that maybe the distribution might be related to Benford’s law.
The second session that got the mathematical side of my brain whirring was by Bryan S. He had first learned about Conway’s “Rational Tangles” a few years ago, and wanted to present it to us. Wonderfully, I had first learned about these from Conway himself when I was in high school attending Mathcamp (and Conway was a guest lecturer). Conway was an electric speaker — and this one lecture of his imprinted itself on my mind. Now skip forward to this year. I had students work on “Explore Math!” projects and one worked on knot theory. I mentioned in my feedback to one student I had a really cool knot theory-adjacent thing I learned and I could show her. She responded saying “yes, please!” Of course it’s been years since I learned Rational Tangles. And it’s like the universe said “Oh, let me bring Bryan S. to you to remind you about all the nitty gritty of it.” And he was fabulous — a marvelous instructor who somehow managed to convey the excitement, weirdness, inquiry, all in a single short session. The crux of the setup is that you have two ropes held by four people:
There are two moves: T(wist) which has the front right person and back right person switch positions, where the front right person brings their rope under the back right person’s rope, and R(otate) where the four people just rotate clockwise. It turns out that by doing seqences of moves like this, such as TTRTRTTRT (etc.), you can get a pretty tangled tangle in the middle of the two ropes. One question — the main one we talked about — is if you can do a series of Ts and Rs to “undo” the tangle and get back into the original position of just two untangled ropes. Amazingly, a few Mathcampers created a digital version of this twisting and rotating and it took me about 20 minutes today to find it even though I knew it existed and I had played with it before. Here it is!
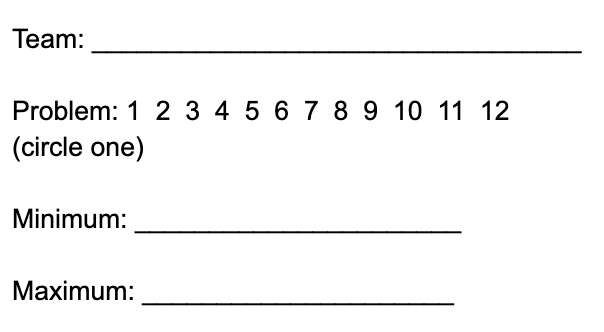
Another session I went to was Chris B’s Estimathon! I participated in my first estimathon at the Park City Math Institute many years ago (and again, a couple years ago). I hated it both times, for a few years. First, I hate estimating. I love thinking and calculating — but Fermi problems? I get really annoyed because I feel I rarely have the adjacent information that can unlock the problem. Second, the other people (both on my team and on all the other teams) were very, very competitive. I prefer a cooperative board game over a competitive board game, and in this, I think I feel similarly. That being said, I really enjoyed doing the estimathon with Chris and our other math conference participants. It was fun because the other people on my team were chill about it, and also let me sort of work alone at times when I got obsessed with a problem. Here are two example questions we were tackling:
Yes, I went to #5 because you can calculate that. Here’s what the scoring sheet looked like:
So you get to guess a minimum value and a maximum value for the range that the answer is in. And your score is ceiling(maximum/minimum). In other words, take the maximum value, divide it by the minimum value, and round up. So min: 2000, max: 3000 would yield a score of 2, and min: 2000 max: 4000 would also yield a score of 2…. but min: 2000, max: 4001 would yield a score of 3. Your goal is to get the lowest score. At the end, Chris gave us the absolute best idea (which I think he got from his colleague Emily). You have kids find out numbers for something that they are passionate about or would be an expert in. It could be “the number of pokemon” or “how many grandchildren does Sameer’s father have?” And then later in the year, you could create an estimathon out of these numbers — where kids have to see what they know about each other and their passions. I love this as a way for people to get to know each other.
There were two additional sessions that I attended, which were about students and math, and I loved both. First was by Jenny W, Lauren B, and Kevin J, and reminded me of the “5 practices” (https://www.nctm.org/Store/Products/5-Practices-for-Orchestrating-Productive-Mathematics-Discussions,-2nd-edition-(Download)/). It’s about using Desmos to highlight and discuss student thinking and to uplift student brilliance. Although I’ve seen many, many presentions on the 5 practices over the year (especially at PCMI), this was a great reminder of a lot of the things I don’t know, and teacher moves I’ve stopped flexing.
The second was by Lauren B called “I am, We are, You are.” It highlighted a few things to me. First, there’s a gap between the demographics of people who teach mathematics (and their identities) and the population of students who learn math (and their identities). She posed a question (of which she thinks the answer is yes): “Is there a way to expand identity in a math class?” I think this is a great question to chew on — and not easy. Especially if you take away classes like statistics or data science from the mix. We played with a super engaging Desmos activity which gave us choice on which data sets to plot against each other, and the fun part was guessing what the scatter plot would look like before we saw it. And she had a quote from Rochelle Gutierrez (who I’ve met before briefly!) which I couldn’t copy down quickly enough, but went something like “Do I have to be a better you in this classroom, or can I be a better me?” This is a student asking the question — essentially saying “Do I have to mold myself to be a miniature version of you, the teacher, to succeed in this room we’re in together?” I also thought that had a lot to chew on… in terms of what we expect from students and the culture that we build together.
Okay, it’s now 9pm and I’ve been at this for way longer than I intended, so to sleep I go.
***
It’s the next day and the conference has finished and I wanted to archive — briefly — the remaining sessions.
First, Hollylynne L. gave the keynote talk “Data Science is Everywhere and For Everyone.” Some takeaways for me are that there are a few large organizations (like NCTM, NCSM, ASA, etc.) that are collaborating to create a united data science position. It’s drafted, and about to be adopted, and has four guiding principles: (1) data science is contextual and multidisciplinary, (2) data science is an investigative process, (3) data science understanding and experiences are for everyone, and (4) data science educators must develop and practice ethical uses of data. The presenter shared her experience ethnographically observing data scientists for 9 months and what traits they exhibited. Then she shared with us that she feels like data science needs to be presented to kids with larger data sets — in terms both of cases but also in number of attributes shared (e.g. not just a survey with one or two questions, but a survey that has a ton of questions!). As an expert on CODAP, she shared how to fluently use it to show data, ask questions, and then interrogate the data. That part was inspiring, and in only a few minutes showcased the power of CODAP (codap.concord.org). Her talk also got me thinking about how our department has over the years shoved all of data science/statistics to our AT Statistics courses as we were making room for everything else we need to teach. Lastly, at the end, she shared a resource I want to follow up on called InSTEP. It is a free online site [https://instepwithdata.org/public/] that is designed to get teachers ready to teach data science and statistics, and it sounds like you learn lots of content, pedagogical moves, and you learn to use various tech tools but primarily CODAP (which is what I want to learn). So yay!
My next session was by Reed H and was an invigorating conversation on Standards Based Grading. He presented a “post mortem” of him implementing SBG in his precalculus classroom for the first time, sharing why he made the switch but also the tradeoffs that occurred. Although our school is moving in a different direction, I was still curious to see how the SBG conversations were going — and it reminded me how much I liked SBG even though it took me 4 years until I had refined it to the point where I could run it fluidly in my standard calculus classes. Reed’s own observations, and the conversations we had as small and large groups, also reminded me of my own path to SBG, and how I now know there is no single flavor of SBG that is going to work for all, because its success is dependent on so many cultural and institutional factors. And there is no magic bullet that is going to make it suddenly easy.
My last session was by Verónica Z and Doru H and was on Linear Programming and Other Means of Optimization. The presenters shared three ways to do optimization without calculus. First, the standard linear programming. The second was something called the “simplex algorithm.” Honestly, I got very confused at this point, because it isn’t in any way intuitive and I think that part of the presentation was meant for people who knew the method. So I ended up stopping my notes and writing “very confused” on my page. (I did find this example that went through the algorithm that I’m curious to read though, to get the crux of the algorithm, but don’t think it will explain “why” it works.) Finally, we learned the TOPSIS algorithm which was just invented in 1991 (“Technique for Order of Preference by Similarity to Ideal Solution”). New math! And the presenter, Verónica, did a really cool job of showing us how to make a decision of which new phone to buy (out of a choice of three) if we were looking at two variables: picture quality and battery life. It’s such a simple algorithm that — at the highest level — has you develop two new “fake” phones that exist — the best phone and the worst phone — one with the best of the traits of the three phones that exist and one with the worst of the traits of the three phones that exist. We plot all three phones and the best “fake” phone and worst “fake” phone. And then we find the “distance” from each of the three phones to the best and worst “fake” phones, and use those distances to rank the phones. Details are in my notes, but I loved learning new math in the universe, and new math to me!
Lastly, the conference was raffling off math art, and although I didn’t win, a new friend did, and she saw how much I coveted them and offered me hers. I demurred and then eventually accepted.
***
Personal Note: Speakers for the most part shared their slides with attendees. So I’ve downloaded the sessions I went to and saved them on my google drive. But I don’t know if they are officially public, so I’m just linking to them here for my own easy access.
One way I start my Advanced Precalculus classes is by having them thinking about n-dimensional cubes. We get there by first exploring the “Painted Block Problem“.
First I have kids look at one of these blocks (I think I give a 5x5x5 block) and have them notice and wonder. Eventually kids wonder what’s on the inside, why different parts are painted different colors, etc. And after some drama, we open up the block, and kids see the new color inside. The question they then are tasked with are how many mini-cubes of each color exist in an n x n x n block.
To be clear, green blocks have 0 exposed faces, yellow have 1 exposed face, blue has 2 exposed faces, and pink has 3 exposed faces.
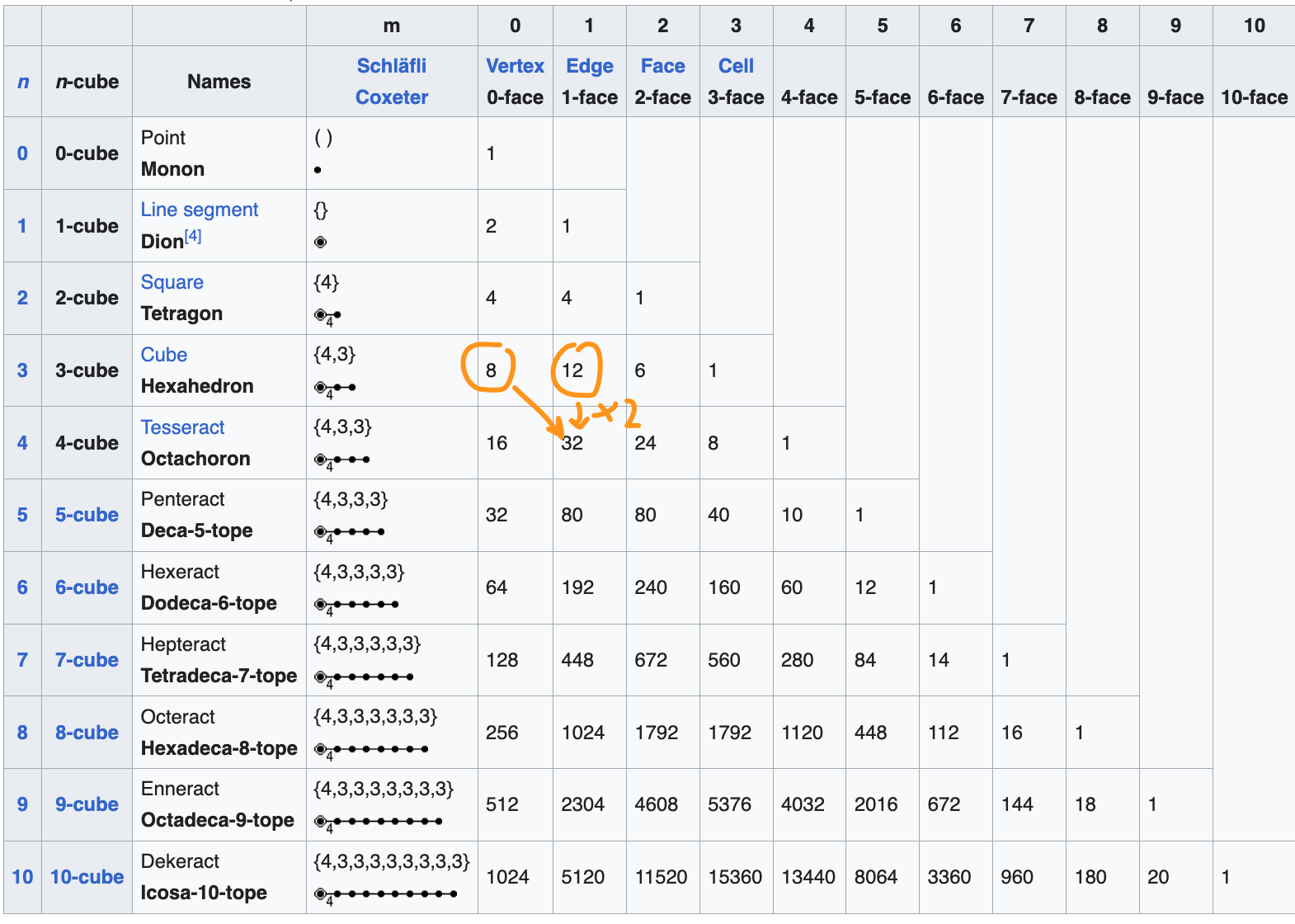
Something that kids eventually stumble upon as they are working on this problem: in a cube, you have 8 vertices (pink), 12 line segments (blue), 6 faces (yellow), and 1 cube (green).
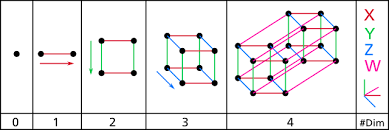
After they solve this problem, I introduce the idea of 0-dimensional cubes (a point), 1-dimensional cubes (a line segment), 2-dimensional cubes (a square), 3-dimensional cubes (a cube), and 4-dimensional cubes (a tesseract)… and how to draw them:
Now let’s look at a 2-dimensional cube (a square). We can see it’s made up of 4 points (0-dimensional cubes), 4 line segments (1-dimensional cubes), and 1 square (2-dimensional cube).
This snip from Wikipedia shows that fact, along with how many smaller dimensional cubes make up a higher dimensional cube.
Finally, here are three questions that I think are fun to ponder:
First, if you look at this chart, there is a really striking pattern…
If you take any number in the chart, double it, and add the number to the left of the number, you’ll get the number in the row below.
The question I ask my kids to answer: why?
Second, without thinking in this recursive way, can you come up with an explicit formula for how many k-dimensional cubes are in a d-dimensional cube? (So if k=1 and d=4, you should get 32.)
(I have only asked my kids this question once, but we had tons of scaffolding. I remember giving it to them the year I devised and solved the problem, and I wanted my kids to have the same gargantuan a-hah moment I had… A couple groups got it, but I realized looking back that the class time we needed to spend on it wasn’t worth the payoff.)
Third, if you add up all the numbers in a row of the chart, you see powers of three. WHAT?!?! ZOMG! Why!?!