Over a month ago, I challenged myself to explain where the line of best fit comes from — conceptually. I started ended Part I with a question:
Our key question is now:
How are we going to be able to choose one line, out of all the possible lines I could draw, that seems like it fits the data well? (One line to rule them all…)
Another way to think of this question: is there a way to measure the “closeness” of the data to the line, so we can decide if Line A or Line B is a better fit for the data? And more importantly, is there an even better line (besides Line A or Line B) that fits the data?
And now, back to our show.
So right now we’re concerned with a measure of closeness. Can we come up with a measurement, a number, which represents how close the data is to a line? And the easy answer is: yes.
The difficulty is that we can come up with a lot of different measurements.
Measurement 1: Shortest Distance
We could measure the shortest distance from each point to the line and add all those distances up.

If I add the distance of all the dashed lines together, I get 
Now let’s try a different line (but with the same points).

If I add the distance of all the dashed lines together, I get 
It’s obvious that the smaller the total sum of those distances is, the “better” the line is to our data. I mean, if we had a bunch of data that fit perfectly on a line, then the sum of all those distances would be 0. And clearly with our two examples, the second line is a HORRIBLE line of best fit, while the first one seems fairly okay (but not great).
So we could use the sum of the perpendicular segments as our measurement. To find the line of best fit, we would say that we have to try out ALL possible lines (there are like, what, infinity of them? hey, you have study hall…) and find the one with the lowest sum. [1]
But, DUM DUM DUM… there are OTHER measurements you could make.
Measurement 2: Horizontal Distance
We could measure the horizontal distance from each point to the line…

If I add the distance of all the solid lines together, I get 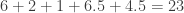
And for a different scenario:

If I add the distance of all the solid lines together, I get 
So if we define “closeness” to be horizontal distance (instead of the closest distance) between a point and a line, the we have a different measurement.
And yet another…
Measurement 3: Vertical Distance
We could measure the vertical distance from each point to the line…

If I add the distance of all the solid lines together, I get 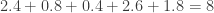
And for a different scenario:

If I add the distance of all the solid lines together, I get 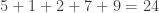
So if we define “closeness” to be vertical distance (instead of the closest distance or the horizontal distance) between a point and a line, the we have a different measurement.
And, in fact, we will see soon (probably in Part III) that there are actually two more measurements we can use.
So which measurement is the best?
You might say: soooo, sir, we have a ton of different measurements. Which one is the right one? The short answer: all of them. Why not? I mean, we wanted to have a measure which tells us how “good” or “bad” a line is when fitting the data, and we have done just that!
It is unsatisfying, but this is how mathematics is. We now have 3 different answers (and there can be more). Each measurement has benefits and drawbacks.
- The benefit of the first measurement is that we are using the closest distance — and that feels (yes, I’m using feeling in math) like a really good thing. The downside is that calculating all those distances from the points to the line is exhausting and algebraically hard.
- The benefit of the second measurement is that calculating the distance between a point and the line is relatively easy. The downside is that the horizontal distance doesn’t feel right.
- The benefit of the third measurement is also that calculating the distance between a point at the line is relatively easy. It also is, conceptually, something deep. If the points are data that have been measured, and the line is a theoretical model for the data, then the distance is the “error” or “difference” between the measured value and the theoretical value. We are summing errors and saying that the line which the smallest sum (least total errors) is minimal. The downside is that it feels better than the second measurement, but less good than the first measurement.
But yeah, you’re upset. You wanted there to be inherently one right answer. We — using our brains — have come up with some proposals. Each have merits. We’ll soon see hone in on one type of measurement that we will use, and talk about the merits of it, and why everyone uses it so much so that it has become the standard measurement to find The Line of Best Fit.
For now, relax. We’ve done something great. Say we gave two of your friends the set of points above and had each one hand draw the line of best fit. You can decide which one did a better job just by adding a bunch of little line segments together. In fact, you have three different ways of deciding, and you have a logical justification for each!
[1] Of course, if you’re a super argumentative student, you might ask: “what if there are two, or even more, lines that have the same lowest measurement?” Well, I love that question. It’s a wonderful question. And worth investigating. Just not right here, right now. And yes, believe it or not, we will check all infinity lines soon enough. It’s possible. Math gives us shortcuts.

This is a neat series, thanks. And Part I has a nice discussion. I’ll try to contribute some discussion in Part II:
You have a bunch of points in R^2, and you’re trying to find the best 1-dimensional object (line) that summarizes (fits) them.
How about backing up a dimension for a simpler (but possibly more confusing, at first!) problem — how about summarizing (or fitting) a bunch of points in R^1 (a line) with one point?
Given data as {-1,1,5,6,7,100}, what single point best fits this? Should we minimize the distances (answer: anything between 5 and 6 is equally good)? Or minimize the sum of the squared distances (answer: use the mean)? What advantages/disadvantages do each of these have? What theoretical problem do they solve? (E.g., suppose these are data sampled from some distribution, maybe a normal distribution. And you’d really like to know the mean/median/mode — same thing in this case — of that distribution?)
Anyway, just some thoughts. I could expand on them or point to references sometime, but maybe that’s not the goal right now. Thanks Sam!
Ohhh, I love the idea of starting with the simpler case.
I don’t really gave a goal — I’m not doing this for my classes or anything. I just wanted to see what I make of it. If I were to teach it, the idea of starting simple (with a 1D set of data) is AMAZING. I honestly don’t know why I didn’t think of it!
If I were more ambitious and have thought of it, I would definitely have done it this way first. Thank you!
Aww, thanks. Glad you like the idea!
This is great, as is the idea of starting with a simpler case.
Definitely using this when the time comes.
I always find this one really hard to wrap my head around, but my problem is that I’m attracted to geometry rather than statistics. Geometrically, that perpendicular distance definition is the most elegant, but I’ve become convinced that it doesn’t actually make any sense to use.
essentially statistical/applied. When you think about lines of best fit, usually you are fitting to a scatterplot of data, that came from somewhere measuring something. Now the stuff on the x-axis is the independent measurement, like time. The stuff on the y-axis is the stuff you’re hoping will fit into a nice pattern–maybe height. When you have a line, you’re usually using it to say: if the time is [25 days] the height is about [14 inches] and you measure your error in how different the prediction is from the actual height–you’re not thinking about it as being an error in how many days different your answer is, so error is something that happens to dependent variables–vertical distance. Back to the geometry–what happens if you take a perpendicular distance approach? When you do that, it’s very dependent on your units, so, if you are measuring your independent axis in days, and your dependent axis in feet, you get a different line of best fit than if you measure your independent axis in days and your dependent axis in inches, because that change in scale changes which lines are perpendicular.
Both dependent and independent variables usually have errors associated with them. What you really want for a fit is something like (xdifference/xerrorrange)^2 + (ydifference/yerrorrange)^2.
@LSquared: This is a very good point that if your goal is to predict the variable on the y-axis from the variable on the x-axis, it makes sense to use vertical distance (where if your goal is reversed, the opposite is good). We could get into the reasons that that makes good statistical sense…
I would only add that ordinary regression can appeal to geometric intuition in a different way: Your 5 data points can be thought of as a vector in R^5. The possible predictions or “fits” for those data points form a plane in R^5 (one dimension for varying the intercept, another for varying the slope). The “best fit” if you’re minimizing sum of the squared error is the projection of that point in R^5 onto that plane in R^5. Or minimizing other “objective functions” correspond to minimizing other distances in R^5.
The point here is to turn the many points and many (vertical) distances in the problem framed in R^2 into one point and one distance (just the ordinary distance, no longer “vertical” or special in any way) in R^5.
Thank you for including me in you blogroll. Your readers may want to see my blog which contains more than 50 GeoGebra tutorials.
http://mathandmultimedia.com/geogebra/